

The Transformative Power of Reinforcement Learning: Shaping the Future of AI and Automation
Affiliate disclosure: This article may contain affiliate links. Recommendations are independent and editorially driven.
In the vast and rapidly evolving landscape of artificial intelligence, a particular paradigm stands out for its unique approach to learning: reinforcement learning. Unlike traditional supervised learning, which relies on labeled datasets, or unsupervised learning, which uncovers patterns in unlabeled data, reinforcement learning empowers intelligent agents to learn optimal behaviors through direct interaction with an environment. It’s a method inspired by behavioral psychology, where an agent observes its state, takes an action, receives a reward or penalty, and iteratively refines its strategy to maximize cumulative rewards over time. This trial-and-error process, fundamentally rooted in exploration and exploitation, has proven to be incredibly powerful, driving breakthroughs across an astonishing array of domains from robotics and gaming to complex resource management and scientific discovery.
As we navigate through 2026, the influence of reinforcement learning is becoming increasingly pervasive. It’s no longer just a theoretical concept confined to research labs; it’s actively shaping the tools and systems that define our emerging technological future. From powering the autonomous vehicles that promise to revolutionize transportation to optimizing the intricate logistics of global supply chains, reinforcement learning is at the heart of systems designed to learn, adapt, and make intelligent decisions in dynamic and uncertain environments. Its ability to solve problems where explicit programming is difficult or impossible makes it a cornerstone technology for the next generation of AI applications, pushing the boundaries of what machines can achieve autonomously.
This comprehensive guide delves deep into the world of reinforcement learning, unpacking its foundational principles, exploring its most impactful algorithms, showcasing its diverse applications, and peering into its promising future. We will examine how this fascinating field is not only advancing the capabilities of AI but also contributing to the broader trends of automation, intelligent systems, and the future of work. Whether you’re an AI enthusiast, a technology professional, or simply curious about the forces shaping tomorrow, understanding reinforcement learning is crucial for grasping the trajectory of modern AI and its profound societal implications.
Introduction to Reinforcement Learning: Beyond Supervised and Unsupervised Methods
To truly appreciate the significance of reinforcement learning, it’s essential to first understand its position within the broader machine learning ecosystem. Traditional machine learning is often categorized into three primary paradigms: supervised learning, unsupervised learning, and reinforcement learning. Each addresses different types of problems and leverages distinct methodologies for knowledge acquisition.
Defining Reinforcement Learning: Agents, Environments, States, Actions, and Rewards
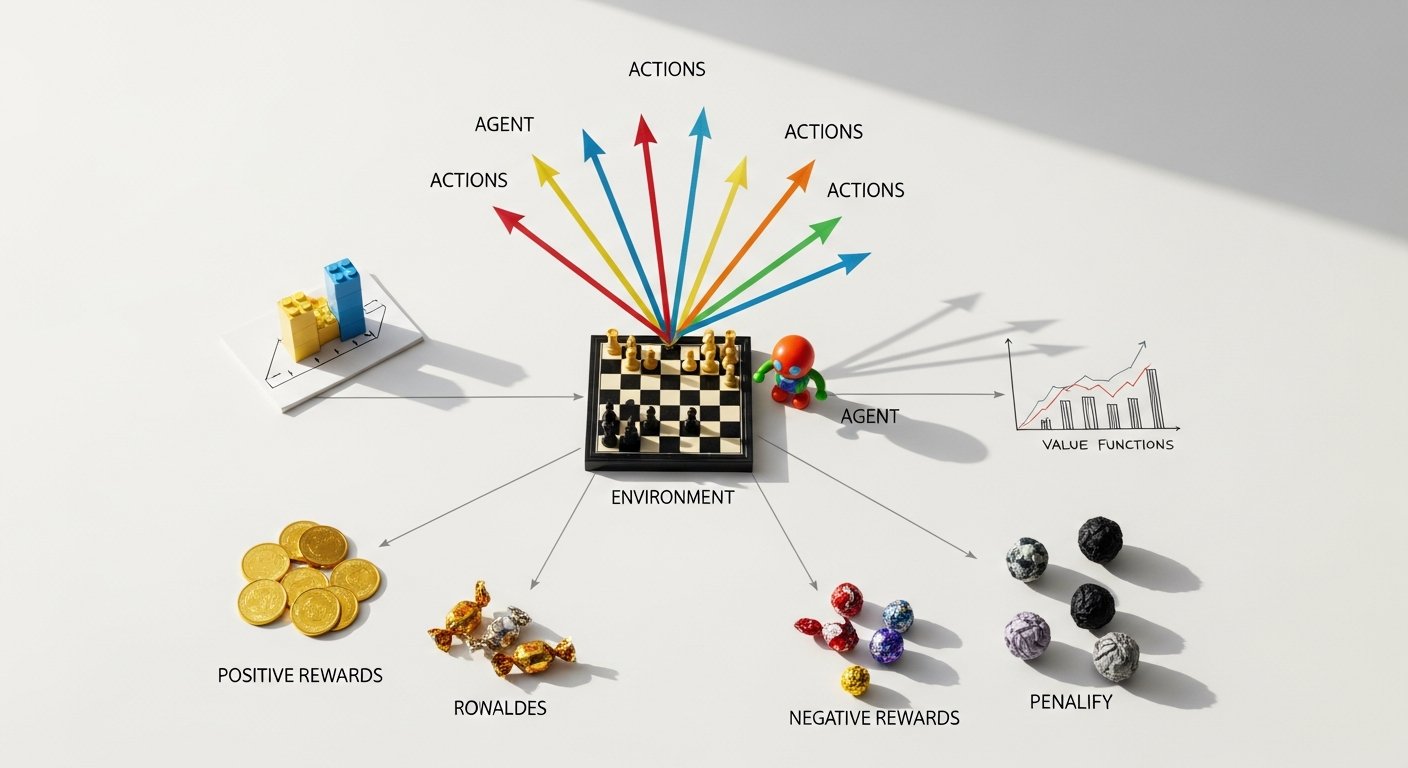
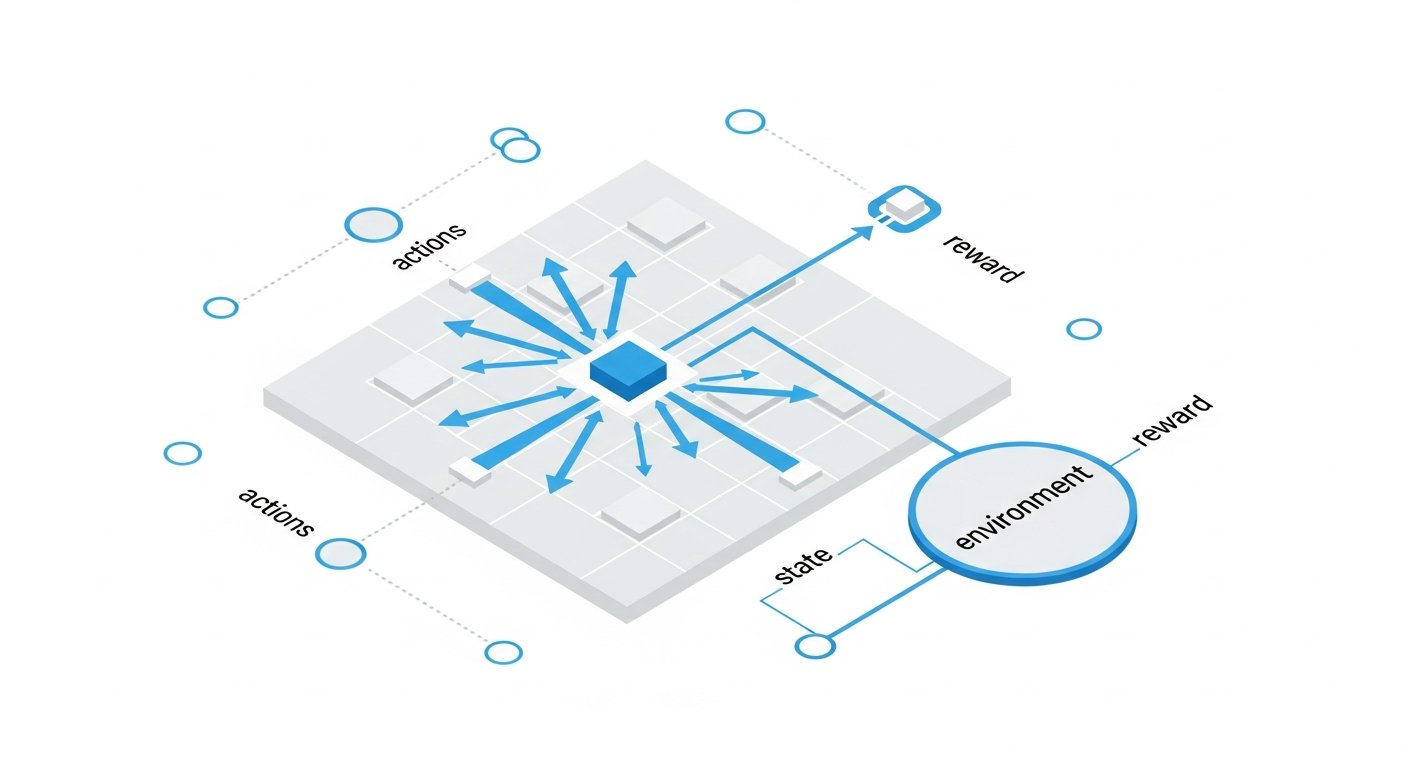
At its core, reinforcement learning revolves around a fundamental interaction model. Imagine an agent operating within an environment. The agent’s goal is to learn a policy – a mapping from observed states of the environment to actions – that maximizes its cumulative reward over time. This interaction can be broken down into several key components:
- Agent: The learner or decision-maker. This could be a robot, an AI in a game, a recommender system, or an autonomous vehicle controller.
- Environment: Everything outside the agent, with which the agent interacts. It defines the context, rules, and consequences of the agent’s actions.
- State (S): A snapshot or description of the current situation of the environment and agent at a given time. For a robot, this might include its joint angles and sensor readings; for a game AI, it could be the positions of all pieces on a board.
- Action (A): A move or decision made by the agent at a given state. Actions change the state of the environment.
- Reward (R): A scalar feedback signal provided by the environment to the agent after taking an action. A positive reward encourages the behavior, while a negative reward (penalty) discourages it. The reward signal is central to guiding the agent’s learning process.
- Policy (π): The agent’s strategy; it maps states to actions, dictating what action the agent should take in any given state. The ultimate goal of reinforcement learning is to find an optimal policy (π*).
- Value Function (V or Q): A prediction of the future reward an agent can expect from a given state or state-action pair under a particular policy.
This continuous cycle of observation, action, and reward feedback forms the bedrock of reinforcement learning. The agent learns not from direct instruction but from the consequences of its choices, gradually improving its policy through repeated interactions.
The Learning Loop: Trial, Error, and Optimization
The learning process in reinforcement learning is inherently iterative and experimental. It can be visualized as a loop:
- The agent observes the current state of the environment.
- Based on its current policy, the agent selects and performs an action.
- The environment transitions to a new state, and the agent receives a numerical reward (or penalty) for its action.
- The agent updates its policy based on the new state, action, and reward, aiming to choose actions that lead to higher cumulative future rewards.
- This loop continues until the agent has learned an optimal (or near-optimal) policy that consistently maximizes its long-term return.
This trial-and-error process is what gives reinforcement learning its distinctive power. Agents can discover highly sophisticated and non-obvious strategies that might be impossible for humans to explicitly program. Think of AlphaGo mastering the game of Go, not by being programmed with human strategies, but by playing against itself millions of times and discovering novel tactics.
Key Distinctions from Other AI Paradigms
To further contextualize reinforcement learning, let’s highlight its key differences from supervised and unsupervised learning:
- Supervised Learning: Requires a dataset of labeled examples, where each input is paired with its correct output. The model learns to map inputs to outputs. Examples include image classification (dog/cat) or spam detection. RL, in contrast, doesn’t need explicit “correct” action labels; it learns from reward signals.
- Unsupervised Learning: Works with unlabeled data, aiming to find inherent patterns or structures within the data. Examples include clustering (grouping similar customers) or dimensionality reduction. Unlike RL, unsupervised learning doesn’t involve an agent interacting with an environment to make sequential decisions for a specific goal.
- Delayed Rewards: A critical characteristic of RL is that rewards are often delayed. An action taken now might not yield a significant reward until many steps later, or it might even lead to a temporary penalty before a large future gain. The agent must learn to attribute rewards to the sequence of actions that led to them, a concept known as the credit assignment problem.
- Sequential Decision Making: RL problems inherently involve a sequence of decisions where each action influences subsequent states and available actions. This dynamic interaction is absent in most supervised and unsupervised tasks.
- No Labeled Data: Instead of labeled data, RL relies on reward signals. The agent learns by exploring the environment and experiencing the consequences of its actions directly.
These distinctions underscore why reinforcement learning is uniquely suited for problems requiring autonomous decision-making in complex, dynamic, and often uncertain environments, making it a pivotal technology for future AI advancements.
Core Concepts and Principles of Reinforcement Learning
Delving deeper into reinforcement learning requires understanding the mathematical and conceptual frameworks that underpin its algorithms. These principles provide the bedrock for how agents learn to make optimal sequential decisions.
Markov Decision Processes (MDPs): The Mathematical Framework
The vast majority of reinforcement learning problems can be formally modeled as Markov Decision Processes (MDPs). An MDP is a mathematical framework for sequential decision-making in environments where outcomes are partly random and partly under the control of a decision-maker. An MDP is defined by a tuple (S, A, P, R, γ):
- S (States): A finite set of states in the environment.
- A (Actions): A finite set of actions available to the agent in each state.
- P (Transition Probabilities): A probability distribution P(s’ | s, a) that defines the probability of transitioning to state s’ from state s after taking action a. This captures the dynamic nature of the environment.
- R (Reward Function): A function R(s, a, s’) that defines the reward received after transitioning from state s to state s’ by taking action a.
- γ (Discount Factor): A scalar value between 0 and 1 (inclusive). It determines the present value of future rewards. A high γ (close to 1) means future rewards are considered very important, encouraging long-term planning. A low γ (close to 0) makes the agent myopic, focusing only on immediate rewards.
The “Markov” property implies that the future is conditionally independent of the past given the present state. In simpler terms, the next state and reward depend only on the current state and the action taken, not on the entire history of how the agent got to the current state. This simplification is crucial for making many RL problems tractable.
Policies, Value Functions, and Q-Learning
The ultimate goal in an MDP is to find an optimal policy (π*), which is a strategy that maximizes the agent’s expected cumulative discounted reward over the long run. To achieve this, reinforcement learning algorithms often rely on two key concepts:
- Policy (π): As discussed, a policy is a rule that an agent follows to choose actions. It can be deterministic (π(s) = a) or stochastic (π(a|s) = probability of taking action a in state s).
- Value Function: Quantifies how “good” it is for an agent to be in a particular state or to take a particular action in a state. There are two main types:
- State-Value Function (Vπ(s)): The expected return (total discounted reward) an agent can expect starting from state s and following policy π thereafter.
- Action-Value Function (Qπ(s, a)): The expected return an agent can expect starting from state s, taking action a, and then following policy π thereafter. Q-values are particularly important because if you know the optimal Q-value for all state-action pairs (Q*(s, a)), you can easily derive the optimal policy by simply choosing the action that maximizes Q*(s, a) for any given state s.
Q-Learning is one of the most popular and foundational model-free reinforcement learning algorithms. It directly learns the optimal action-value function, Q*(s, a), without requiring a model of the environment’s transition probabilities or reward function. The core update rule for Q-learning is:
Q(s, a) ← Q(s, a) + α [R + γ max_{a'} Q(s', a') - Q(s, a)]
Here, α is the learning rate, R is the immediate reward, γ is the discount factor, s’ is the next state, and max_{a’} Q(s’, a’) represents the maximum Q-value achievable from the next state s’. This update rule allows the agent to iteratively refine its estimates of Q-values based on experience, eventually converging to the optimal Q-values and thus the optimal policy.
Exploration vs. Exploitation: The Fundamental Dilemma
One of the central challenges in reinforcement learning is striking the right balance between exploration and exploitation. This is often referred to as the exploration-exploitation dilemma:
- Exploration: The agent tries new, potentially suboptimal actions to discover more about the environment and potentially find better rewards. This is crucial for discovering optimal strategies that might not be immediately obvious.
- Exploitation: The agent leverages its current knowledge to choose the action that it believes will yield the highest immediate reward based on its current value function estimates. This maximizes rewards in the short term.
If an agent only exploits, it might get stuck in a locally optimal but globally suboptimal strategy. If it only explores, it might never converge on an efficient strategy. Common strategies to manage this dilemma include ε-greedy exploration (where the agent chooses a random action with probability ε and the greedy action with probability 1-ε) and more sophisticated methods like Upper Confidence Bound (UCB) or Thompson Sampling. The balance often shifts over time, with more exploration early in training and more exploitation later on as the agent’s knowledge improves.
Discount Factor and Bellman Equation
The discount factor (γ) plays a crucial role in how an agent values future rewards relative to immediate rewards. A discount factor of 0 means the agent only cares about immediate rewards, making it very short-sighted. A discount factor of 1 means the agent values future rewards equally to immediate rewards, which can lead to infinite returns in continuing tasks and makes the problem harder to converge. Typically, γ is set to a value like 0.9 or 0.99, balancing immediate gratification with long-term strategic planning.
The Bellman Equation is a fundamental equation in dynamic programming and reinforcement learning that decomposes the value function into the immediate reward plus the discounted value of future states. For the optimal action-value function, the Bellman Optimality Equation states:
Q*(s, a) = R(s, a) + γ Σ_{s'} P(s' | s, a) max_{a'} Q*(s', a')
This equation expresses the optimal Q-value for a state-action pair as the sum of the immediate reward for taking that action, plus the discounted maximum expected future reward from the next state. The Bellman equation is central to many RL algorithms, as they often attempt to find a policy that satisfies this recursive relationship, iteratively improving value estimates until optimality is reached. Understanding these core concepts is vital for anyone looking to build or comprehend advanced reinforcement learning systems.
[INLINE IMAGE 1: place after second H2 | alt=”reinforcement learning concept illustration”]
Key Algorithms and Techniques in Reinforcement Learning
The theoretical framework of MDPs and value functions gives rise to a rich diversity of algorithms designed to solve reinforcement learning problems. These algorithms can generally be categorized based on whether they explicitly learn a model of the environment (model-based) or learn directly from experience (model-free), and whether they learn value functions or directly learn policies.
Model-Free RL: Q-Learning, SARSA, and Deep Q-Networks (DQN)
Model-free algorithms are perhaps the most widely used in practical applications because they don’t require prior knowledge of the environment’s dynamics (transition probabilities and reward functions). They learn directly from observed experiences (state, action, reward, next state tuples).
- Q-Learning: As discussed, Q-learning is a prominent off-policy algorithm. “Off-policy” means that the agent learns the optimal Q-function regardless of the policy it is currently following for exploration. It’s often paired with ε-greedy exploration to balance exploring new actions with exploiting known good ones. Q-learning is guaranteed to converge to the optimal Q-values under certain conditions (e.g., discrete state/action spaces, sufficient exploration, appropriate learning rate).
- SARSA (State-Action-Reward-State-Action): SARSA is an on-policy counterpart to Q-learning. “On-policy” means the agent learns the Q-function for the policy it is currently executing, including its exploration strategy. The SARSA update rule is similar but uses the Q-value of the next action *actually taken* by the current policy, rather than the maximum possible Q-value from the next state:
Q(s, a) ← Q(s, a) + α [R + γ Q(s', a') - Q(s, a)]
Where a’ is the action chosen by the current policy in state s’. SARSA tends to be more conservative than Q-learning because it considers the consequences of its exploratory actions when learning. - Deep Q-Networks (DQN): A monumental breakthrough occurred when DeepMind combined Q-learning with deep neural networks, leading to Deep Q-Networks (DQN). In traditional Q-learning, Q-values for each state-action pair are stored in a table. This becomes intractable for environments with large or continuous state spaces (e.g., raw pixel inputs from video games). DQN uses a neural network (a “Q-network”) to approximate the Q-function, mapping states to Q-values for all possible actions. Key innovations of DQN include:
- Experience Replay: Stores past experiences (s, a, r, s’) in a replay buffer and samples mini-batches randomly from it for training. This decorrelates successive samples, addressing the problem of non-stationary data and improving training stability.
- Target Network: Uses a separate, older version of the Q-network (the “target network”) to compute the target Q-values for the update rule. This helps stabilize training by providing a more consistent target for the Q-network to learn from, reducing oscillations.
DQN famously achieved human-level performance across a range of Atari 2600 games using only raw pixel inputs, demonstrating the power of deep reinforcement learning.
Policy Gradient Methods: REINFORCE, Actor-Critic, and A2C/A3C
Instead of learning value functions, policy gradient methods directly learn a parameterized policy that maps states to actions without necessarily computing value estimates. They work by directly searching in the space of policies to find one that maximizes performance (expected return). The core idea is to estimate the gradient of the expected return with respect to the policy’s parameters and then update the parameters in the direction of this gradient.
- REINFORCE (Monte Carlo Policy Gradient): This is one of the simplest policy gradient algorithms. It works by running an entire episode, calculating the return for each state-action pair, and then updating the policy parameters using a Monte Carlo estimate of the gradient. It tends to have high variance in its gradient estimates, which can make training slow or unstable.
- Actor-Critic Methods: These methods combine the strengths of both value-based and policy-based approaches. They consist of two components:
- Actor: The policy network, which decides what action to take.
- Critic: The value function network, which evaluates the action taken by the actor. The critic’s estimate of the value (often called the “advantage function” which measures how much better an action is than the average action from that state) is used to update the actor’s policy, providing a less noisy and more stable gradient signal than REINFORCE.
This synergism helps both components learn more effectively: the actor learns better policies with the critic’s guidance, and the critic learns more accurate value functions by observing the actor’s improved behavior.
- Asynchronous Advantage Actor-Critic (A3C) and Advantage Actor-Critic (A2C): A3C was another significant innovation, allowing multiple agents to explore and learn in parallel on different instances of the environment. Each agent updates a global network asynchronously. This parallelization improves sample efficiency and stability. A2C is a synchronous, single-worker version of A3C that often performs similarly well and is easier to implement. These algorithms leverage the advantage function to reduce variance in policy updates.
Model-Based RL: Planning and Learning from World Models
Model-based reinforcement learning algorithms attempt to learn a model of the environment’s dynamics. This model predicts the next state and reward given a current state and action. Once a model is learned, the agent can use it to plan future actions without needing to interact with the real environment. This can lead to much higher sample efficiency (requiring less real-world interaction) and the ability to perform “mental simulations.”
- Learning the Model: The model itself is often a supervised learning problem, where the agent learns to predict s’ and r from (s, a) pairs collected during real interactions. This can be a neural network.
- Planning with the Model: Once a model is learned, the agent can use techniques like tree search (e.g., Monte Carlo Tree Search used in AlphaGo) or dynamic programming to plan optimal action sequences. It can simulate many possible futures within its learned model and choose the action that leads to the best simulated outcome.
- Examples: AlphaZero (a successor to AlphaGo) combined model-based planning (MCTS) with deep reinforcement learning, using a learned neural network to evaluate positions and guide the search. Recent advancements, such as “world models,” allow agents to learn compressed, predictive models of their environments and then train entirely within these imagined worlds, significantly reducing the need for real-world interactions.
Advanced Techniques: Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC)
The field of reinforcement learning is continuously evolving, with new algorithms addressing limitations of prior methods. Two prominent modern algorithms that have achieved state-of-the-art results in continuous control tasks are PPO and SAC:
- Proximal Policy Optimization (PPO): PPO is an on-policy algorithm that has become very popular due to its simplicity, robustness, and strong performance. It’s an actor-critic method that tries to take the largest possible improvement step on a policy without causing the new policy to diverge too far from the old one, which could lead to instability. It achieves this by using a clipped objective function that constrains policy updates, making it more stable than traditional policy gradient methods. PPO is widely used in OpenAI’s research and is a go-to algorithm for many continuous control tasks.
- Soft Actor-Critic (SAC): SAC is an off-policy actor-critic algorithm that aims to maximize not just the expected return but also the policy’s entropy. By maximizing entropy, the agent is encouraged to explore more and find diverse optimal policies, which can make it more robust and sample-efficient. SAC combines the stability benefits of off-policy learning (using a replay buffer) with an actor-critic structure and a unique entropy regularization term, making it highly effective for complex continuous control problems.
The progression from Q-learning to DQN, then to policy gradient methods like A3C/A2C, and finally to advanced algorithms like PPO and SAC, showcases the rapid innovation in reinforcement learning. These algorithms are the backbone of the intelligent agents driving the next wave of automation and AI capabilities across various industries.
Real-World Applications of Reinforcement Learning
The theoretical elegance and algorithmic sophistication of reinforcement learning truly come to life through its diverse and impactful real-world applications. From complex robotic movements to optimizing vast energy networks, RL is proving to be an indispensable tool for tackling problems that require adaptive, intelligent decision-making in dynamic environments.
Robotics and Autonomous Systems: From Drones to Self-Driving Cars
One of the most intuitive and visually striking applications of reinforcement learning is in robotics. Robots operating in the real world face immense complexity and uncertainty. Traditional programming struggles to account for every possible variable, making RL an ideal solution for teaching robots how to learn and adapt.
- Locomotion and Manipulation: RL has enabled robots to learn highly dexterous manipulation tasks, such as grasping irregular objects, assembling components, or even performing surgical procedures. For locomotion, RL agents can learn to walk, run, or climb in challenging terrains, often discovering gaits that are more efficient or robust than human-engineered ones. Projects involving bipedal robots, quadrupedal robots, and even soft robots have showcased RL’s ability to imbue physical systems with adaptive motor control.
- Autonomous Navigation: Self-driving cars and autonomous drones are prime examples of RL in action. These systems must make continuous, real-time decisions about speed, steering, braking, and path planning while navigating unpredictable environments. RL agents can learn to react to traffic, pedestrians, weather conditions, and unexpected obstacles, continuously optimizing for safety, efficiency, and comfort. Simulators are heavily used to train these agents, reducing the risk and cost of real-world training, with strategies then transferred to physical systems.
- Human-Robot Interaction: RL is also being explored to develop more natural and intuitive human-robot interaction, allowing robots to learn from human demonstrations or adapt their behavior based on human feedback, leading to more collaborative and effective partnerships.
Game AI: Mastering Complex Strategies (AlphaGo, Atari)
The realm of gaming has served as a powerful proving ground for reinforcement learning, demonstrating its capacity to master incredibly complex strategy games. The success of RL in this domain often highlights its ability to discover novel strategies that surpass human intuition.
- Atari Games: DeepMind’s original DQN paper famously demonstrated human-level performance across a suite of classic Atari 2600 games, learning directly from raw pixel inputs. This showed RL’s ability to handle high-dimensional observations and learn diverse control policies.
- AlphaGo and Beyond: Perhaps the most iconic achievement of RL in games is AlphaGo, developed by DeepMind. AlphaGo used deep reinforcement learning and Monte Carlo Tree Search to defeat the world champion of Go, a game far more complex than chess with an astronomical number of possible moves. Subsequent versions like AlphaZero and MuZero generalized this approach to master chess, shogi, and even arbitrary board games without any human domain knowledge, learning purely through self-play.
- Real-time Strategy (RTS) Games: OpenAI Five achieved professional-level performance in Dota 2, a highly complex real-time strategy game with a vast state space, imperfect information, and multi-agent coordination challenges. This demonstrated RL’s capabilities in multi-agent environments with long-term strategic planning.
Resource Management and Optimization: Energy Grids and Supply Chains
Beyond physical agents, reinforcement learning excels at optimizing complex systems and resource allocation, where the goal is to maximize efficiency or minimize waste over time.
- Energy Management: RL algorithms are being deployed to optimize energy consumption in large buildings, data centers, and even entire smart grids. By learning the interplay between energy demand, supply (including renewables), prices, and environmental factors, RL agents can make real-time decisions to reduce costs, enhance sustainability, and improve grid stability. For example, DeepMind used RL to reduce the energy consumed for cooling Google’s data centers by 40%.
- Supply Chain and Logistics: Managing vast and intricate supply chains involves optimizing inventory levels, routing fleets, scheduling deliveries, and responding to disruptions. RL can learn optimal policies for these tasks, dynamically adapting to changing demand, transport availability, and unforeseen events, leading to significant cost savings and improved delivery times.
- Traffic Control: RL can optimize traffic light timings and lane assignments in urban areas to alleviate congestion, reduce travel times, and improve overall traffic flow.
Personalized Recommendations and Advertising
Many online platforms leverage RL to provide highly personalized experiences, enhancing user engagement and business outcomes.
- Recommender Systems: Instead of static recommendations, RL can learn to dynamically adjust recommendations based on a user’s real-time interactions, feedback, and evolving preferences. By treating the user as the environment and the recommendations as actions, RL systems can maximize long-term engagement or satisfaction. This is particularly valuable for streaming services, e-commerce platforms, and content aggregators.
- Online Advertising: RL agents can optimize bidding strategies in real-time advertising auctions, choose which ads to display to which users, and even design ad placements, aiming to maximize click-through rates, conversions, or revenue while adhering to budget constraints.
Finance and Algorithmic Trading
The financial sector, characterized by its highly dynamic and uncertain nature, presents fertile ground for reinforcement learning applications.
- Algorithmic Trading: RL agents can learn to execute complex trading strategies, optimizing buy/sell decisions, portfolio management, and risk assessment in high-frequency trading environments. They can adapt to market fluctuations, learn from historical data, and react to real-time information to maximize returns while managing risk.
- Portfolio Optimization: RL can help in dynamically adjusting asset allocations in investment portfolios to achieve specific financial goals, taking into account market volatility and long-term trends.
- Fraud Detection: While often a supervised learning problem, RL can be used to adaptively refine fraud detection strategies, learning from the evolving tactics of fraudsters and making sequential decisions on how to investigate or block suspicious activities.
Healthcare: Drug Discovery and Treatment Personalization
The potential of reinforcement learning to revolutionize healthcare is immense, particularly in areas requiring highly individualized and adaptive approaches.
- Drug Discovery and Design: RL can accelerate the drug discovery process by autonomously navigating chemical spaces to design novel molecules with desired properties. Agents can learn to synthesize compounds, predict their efficacy, and optimize molecular structures for specific therapeutic targets, vastly reducing the time and cost associated with traditional methods.
- Personalized Treatment Plans: For chronic diseases or complex conditions, RL can help develop adaptive treatment plans. By treating a patient’s physiological state as the environment and medical interventions (medication dosage, therapy schedules) as actions, RL can learn optimal strategies to manage symptoms, prevent progression, and improve patient outcomes over time, tailoring treatment to individual responses.
- Medical Robotics: Surgical robots equipped with RL capabilities can perform precise and adaptive movements, assisting surgeons or even carrying out delicate procedures autonomously under supervision.
[INLINE IMAGE 2: place after fourth H2 | alt=”reinforcement learning comparison illustration”]
These diverse applications underscore the versatility and transformative potential of reinforcement learning across a multitude of sectors. As computational power increases and algorithms become more sophisticated, the scope for RL to solve even more complex challenges will only expand, driving innovation in autonomous systems, optimization, and intelligent decision-making across industries.
Learn more about the ethical implications of advanced AI systems.
The Synergies: Reinforcement Learning and Other AI Domains
Reinforcement learning rarely operates in isolation. Its true power often emerges when it is integrated with, or leverages techniques from, other branches of artificial intelligence. These synergies create more robust, versatile, and intelligent systems, capable of tackling even more intricate problems.
Deep Reinforcement Learning: Combining RL with Deep Learning
The most prominent and impactful synergy in modern AI is the convergence of reinforcement learning and deep learning, giving rise to Deep Reinforcement Learning (DRL). This combination has been the driving force behind many of the headline-grabbing achievements in RL over the past decade.
- Addressing High-Dimensional Data: Deep learning, particularly deep neural networks, excels at processing and extracting meaningful features from high-dimensional, raw data such as images, video, and raw sensor readings. In traditional RL, representing states and actions for such complex inputs was a major bottleneck. DRL overcomes this by using deep neural networks as function approximators for the policy and/or value functions. Instead of a tabular Q-function, a deep Q-network (DQN) maps raw pixel inputs directly to action values.
- Feature Extraction and Generalization: Deep neural networks automatically learn hierarchical representations of data. This means a DRL agent can perceive the environment directly through its raw sensory input and generalize its learned policies to unseen states, making it incredibly powerful for tasks like game playing (from pixels), robotics (from camera feeds), and autonomous driving.
- End-to-End Learning: DRL often enables end-to-end learning, where the agent learns directly from raw inputs to output actions, minimizing the need for handcrafted features or intermediate representations. This simplifies system design and allows the agent to discover optimal feature representations itself.
DQN, A3C, PPO, and SAC are all prime examples of deep reinforcement learning algorithms, demonstrating how deep learning provides the perceptual and representational capabilities that allow RL to scale to complex, real-world problems.
Imitation Learning and Inverse Reinforcement Learning
While reinforcement learning typically learns from reward signals, sometimes it’s more efficient or safer to learn from expert demonstrations, particularly when designing a reward function is difficult or dangerous.
- Imitation Learning (Learning from Demonstration): In imitation learning, an agent learns to mimic the behavior of an expert by observing demonstrations (state-action pairs). It’s essentially a supervised learning problem where the expert’s actions are treated as labels. This is useful for bootstrapping RL agents, allowing them to learn basic skills quickly before refining them with RL, or for tasks where designing a reward function is hard (e.g., driving, intricate manipulation). Behavioral cloning is a common form of imitation learning.
- Inverse Reinforcement Learning (IRL): IRL takes the opposite approach. Instead of learning a policy from a reward function, IRL infers the underlying reward function that explains an expert’s observed behavior. This is incredibly powerful because it can solve the “reward engineering problem” – the challenge of designing effective reward functions for complex tasks. Once a reward function is learned from expert demonstrations, a standard RL algorithm can then be used to find an optimal policy, potentially even surpassing the expert’s performance. For example, in autonomous driving, IRL could infer a reward function that balances safety, speed, and comfort by observing human drivers, rather than explicitly programming these trade-offs.
Reinforcement Learning in Generative AI and Large Language Models
The recent explosion of generative AI, particularly large language models (LLMs), has created new avenues for reinforcement learning. RL is playing a critical role in refining and aligning these powerful models.
- Reinforcement Learning from Human Feedback (RLHF): This technique has been instrumental in the success of models like ChatGPT. LLMs initially generate text based on predicting the next token. However, their raw output might be unhelpful, biased, or even harmful. RLHF uses human preferences to train a “reward model,” which then provides feedback to the LLM. The LLM then fine-tunes its generation policy using reinforcement learning (e.g., PPO) to produce outputs that are aligned with human values, helpfulness, and safety criteria. This is a powerful way to guide complex generative models towards desired behaviors without explicit programming for every possible output.
- Controlling Generative Processes: RL can also be used to control the generation process itself in other generative models, such as image generation, to ensure that the generated content meets specific criteria or constraints, or to explore latent spaces more effectively.
Explainable Reinforcement Learning (XRL): Towards Transparency
As RL systems become more autonomous and are deployed in critical applications, understanding their decision-making process becomes paramount. This gives rise to Explainable Reinforcement Learning (XRL), a field that borrows techniques from Explainable AI (XAI).
- Understanding Policy Decisions: XRL aims to provide insights into why an RL agent takes certain actions in particular states. This can involve visualizing the agent’s attention, analyzing feature importance in the neural networks, or extracting simpler, human-interpretable policies from complex learned ones.
- Debugging and Trust: Explanations are crucial for debugging agent failures, building trust with human users, and ensuring ethical and fair behavior, especially in high-stakes domains like healthcare or finance. Methods include saliency maps, causal explanations, and counterfactual reasoning.
These interconnections demonstrate that reinforcement learning is not an isolated discipline but a dynamically interacting component within the broader AI landscape. Its ability to learn from interaction and optimize for long-term goals makes it a powerful partner for other AI technologies, collectively pushing the boundaries of what intelligent systems can achieve in 2026 and beyond.
Challenges and Limitations of Reinforcement Learning
Despite its remarkable successes and transformative potential, reinforcement learning is not without its significant challenges and limitations. Addressing these issues is a key focus of ongoing research and development, particularly as we push RL towards more complex, real-world deployments.
Sample Efficiency and Data Requirements
One of the most frequently cited limitations of reinforcement learning is its often-prohibitive demand for data or interaction time with the environment.
- High Number of Interactions: RL agents typically require a vast number of trials and errors to learn optimal policies. For physical robots, this translates to expensive and time-consuming real-world interaction, leading to wear and tear. In simulations, even though interactions are cheaper, the sheer volume can still demand substantial computational resources and time.
- Difficulty in Real-World Application: While games like Atari and Go provide convenient, fast-resetting environments, applying RL to real-world tasks like autonomous driving or complex robotics often means a single “episode” can last hours, and collecting enough diverse experience is incredibly challenging and often impractical.
- Contrast with Supervised Learning: Unlike supervised learning, where a single labeled example can teach a feature, in RL, an agent might need to explore many different scenarios to understand the consequences of its actions.
Researchers are actively working on solutions like model-based RL (learning an internal model of the environment to simulate experiences), offline RL (learning from pre-collected, static datasets), and transfer learning (applying knowledge from one task/environment to another) to improve sample efficiency.
The Curse of Dimensionality
The “curse of dimensionality” refers to how exponentially the volume of space (and thus the number of samples needed) increases as the number of dimensions (states or actions) grows. This problem plagues reinforcement learning:
- Large State Spaces: If an environment has many observable variables, or if the state is represented by raw sensory input (like high-resolution images or videos), the number of possible states becomes astronomically large. Tabular methods (like basic Q-learning) are simply infeasible.
- Continuous State/Action Spaces: Many real-world problems involve continuous states (e.g., a robot’s joint angles, vehicle speed) and continuous actions (e.g., steering angle, motor torque). Discretizing these spaces can lead
The Transformative Power of Reinforcement Learning: Shaping the Future of AI and Automation
Affiliate disclosure: This article may contain affiliate links. Recommendations are independent and editorially driven.
In the vast and rapidly evolving landscape of artificial intelligence, a particular paradigm stands out for its unique approach to learning: reinforcement learning. Unlike traditional supervised learning, which relies on labeled datasets, or unsupervised learning, which uncovers patterns in unlabeled data, reinforcement learning empowers intelligent agents to learn optimal behaviors through direct interaction with an environment. It’s a method inspired by behavioral psychology, where an agent observes its state, takes an action, receives a reward or penalty, and iteratively refines its strategy to maximize cumulative rewards over time. This trial-and-error process, fundamentally rooted in exploration and exploitation, has proven to be incredibly powerful, driving breakthroughs across an astonishing array of domains from robotics and gaming to complex resource management and scientific discovery.
As we navigate through 2026, the influence of reinforcement learning is becoming increasingly pervasive. It’s no longer just a theoretical concept confined to research labs; it’s actively shaping the tools and systems that define our emerging technological future. From powering the autonomous vehicles that promise to revolutionize transportation to optimizing the intricate logistics of global supply chains, reinforcement learning is at the heart of systems designed to learn, adapt, and make intelligent decisions in dynamic and uncertain environments. Its ability to solve problems where explicit programming is difficult or impossible makes it a cornerstone technology for the next generation of AI applications, pushing the boundaries of what machines can achieve autonomously.
This comprehensive guide delves deep into the world of reinforcement learning, unpacking its foundational principles, exploring its most impactful algorithms, showcasing its diverse applications, and peering into its promising future. We will examine how this fascinating field is not only advancing the capabilities of AI but also contributing to the broader trends of automation, intelligent systems, and the future of work. Whether you’re an AI enthusiast, a technology professional, or simply curious about the forces shaping tomorrow, understanding reinforcement learning is crucial for grasping the trajectory of modern AI and its profound societal implications.
Introduction to Reinforcement Learning: Beyond Supervised and Unsupervised Methods
To truly appreciate the significance of reinforcement learning, it’s essential to first understand its position within the broader machine learning ecosystem. Traditional machine learning is often categorized into three primary paradigms: supervised learning, unsupervised learning, and reinforcement learning. Each addresses different types of problems and leverages distinct methodologies for knowledge acquisition.
Defining Reinforcement Learning: Agents, Environments, States, Actions, and Rewards
At its core, reinforcement learning revolves around a fundamental interaction model. Imagine an agent operating within an environment. The agent’s goal is to learn a policy – a mapping from observed states of the environment to actions – that maximizes its cumulative reward over time. This interaction can be broken down into several key components:
- Agent: The learner or decision-maker. This could be a robot, an AI in a game, a recommender system, or an autonomous vehicle controller.
- Environment: Everything outside the agent, with which the agent interacts. It defines the context, rules, and consequences of the agent’s actions.
- State (S): A snapshot or description of the current situation of the environment and agent at a given time. For a robot, this might include its joint angles and sensor readings; for a game AI, it could be the positions of all pieces on a board.
- Action (A): A move or decision made by the agent at a given state. Actions change the state of the environment.
- Reward (R): A scalar feedback signal provided by the environment to the agent after taking an action. A positive reward encourages the behavior, while a negative reward (penalty) discourages it. The reward signal is central to guiding the agent’s learning process.
- Policy (π): The agent’s strategy; it maps states to actions, dictating what action the agent should take in any given state. The ultimate goal of reinforcement learning is to find an optimal policy (π*).
- Value Function (V or Q): A prediction of the future reward an agent can expect from a given state or state-action pair under a particular policy.
This continuous cycle of observation, action, and reward feedback forms the bedrock of reinforcement learning. The agent learns not from direct instruction but from the consequences of its choices, gradually improving its policy through repeated interactions.
The Learning Loop: Trial, Error, and Optimization
The learning process in reinforcement learning is inherently iterative and experimental. It can be visualized as a loop:
- The agent observes the current state of the environment.
- Based on its current policy, the agent selects and performs an action.
- The environment transitions to a new state, and the agent receives a numerical reward (or penalty) for its action.
- The agent updates its policy based on the new state, action, and reward, aiming to choose actions that lead to higher cumulative future rewards.
- This loop continues until the agent has learned an optimal (or near-optimal) policy that consistently maximizes its long-term return.
This trial-and-error process is what gives reinforcement learning its distinctive power. Agents can discover highly sophisticated and non-obvious strategies that might be impossible for humans to explicitly program. Think of AlphaGo mastering the game of Go, not by being programmed with human strategies, but by playing against itself millions of times and discovering novel tactics.
Key Distinctions from Other AI Paradigms
To further contextualize reinforcement learning, let’s highlight its key differences from supervised and unsupervised learning:
- Supervised Learning: Requires a dataset of labeled examples, where each input is paired with its correct output. The model learns to map inputs to outputs. Examples include image classification (dog/cat) or spam detection. RL, in contrast, doesn’t need explicit “correct” action labels; it learns from reward signals.
- Unsupervised Learning: Works with unlabeled data, aiming to find inherent patterns or structures within the data. Examples include clustering (grouping similar customers) or dimensionality reduction. Unlike RL, unsupervised learning doesn’t involve an agent interacting with an environment to make sequential decisions for a specific goal.
- Delayed Rewards: A critical characteristic of RL is that rewards are often delayed. An action taken now might not yield a significant reward until many steps later, or it might even lead to a temporary penalty before a large future gain. The agent must learn to attribute rewards to the sequence of actions that led to them, a concept known as the credit assignment problem.
- Sequential Decision Making: RL problems inherently involve a sequence of decisions where each action influences subsequent states and available actions. This dynamic interaction is absent in most supervised and unsupervised tasks.
- No Labeled Data: Instead of labeled data, RL relies on reward signals. The agent learns by exploring the environment and experiencing the consequences of its actions directly.
These distinctions underscore why reinforcement learning is uniquely suited for problems requiring autonomous decision-making in complex, dynamic, and often uncertain environments, making it a pivotal technology for future AI advancements.
Core Concepts and Principles of Reinforcement Learning
Delving deeper into reinforcement learning requires understanding the mathematical and conceptual frameworks that underpin its algorithms. These principles provide the bedrock for how agents learn to make optimal sequential decisions.
Markov Decision Processes (MDPs): The Mathematical Framework
The vast majority of reinforcement learning problems can be formally modeled as Markov Decision Processes (MDPs). An MDP is a mathematical framework for sequential decision-making in environments where outcomes are partly random and partly under the control of a decision-maker. An MDP is defined by a tuple (S, A, P, R, γ):
- S (States): A finite set of states in the environment.
- A (Actions): A finite set of actions available to the agent in each state.
- P (Transition Probabilities): A probability distribution P(s’ | s, a) that defines the probability of transitioning to state s’ from state s after taking action a. This captures the dynamic nature of the environment.
- R (Reward Function): A function R(s, a, s’) that defines the reward received after transitioning from state s to state s’ by taking action a.
- γ (Discount Factor): A scalar value between 0 and 1 (inclusive). It determines the present value of future rewards. A high γ (close to 1) means future rewards are considered very important, encouraging long-term planning. A low γ (close to 0) makes the agent myopic, focusing only on immediate rewards.
The “Markov” property implies that the future is conditionally independent of the past given the present state. In simpler terms, the next state and reward depend only on the current state and the action taken, not on the entire history of how the agent got to the current state. This simplification is crucial for making many RL problems tractable.
Policies, Value Functions, and Q-Learning
The ultimate goal in an MDP is to find an optimal policy (π*), which is a strategy that maximizes the agent’s expected cumulative discounted reward over the long run. To achieve this, reinforcement learning algorithms often rely on two key concepts:
- Policy (π): As discussed, a policy is a rule that an agent follows to choose actions. It can be deterministic (π(s) = a) or stochastic (π(a|s) = probability of taking action a in state s).
- Value Function: Quantifies how “good” it is for an agent to be in a particular state or to take a particular action in a state. There are two main types:
- State-Value Function (Vπ(s)): The expected return (total discounted reward) an agent can expect starting from state s and following policy π thereafter.
- Action-Value Function (Qπ(s, a)): The expected return an agent can expect starting from state s, taking action a, and then following policy π thereafter. Q-values are particularly important because if you know the optimal Q-value for all state-action pairs (Q*(s, a)), you can easily derive the optimal policy by simply choosing the action that maximizes Q*(s, a) for any given state s.
Q-Learning is one of the most popular and foundational model-free reinforcement learning algorithms. It directly learns the optimal action-value function, Q*(s, a), without requiring a model of the environment’s transition probabilities or reward function. The core update rule for Q-learning is:
Q(s, a) ← Q(s, a) + α [R + γ max_{a'} Q(s', a') - Q(s, a)]
Here, α is the learning rate, R is the immediate reward, γ is the discount factor, s’ is the next state, and max_{a’} Q(s’, a’) represents the maximum Q-value achievable from the next state s’. This update rule allows the agent to iteratively refine its estimates of Q-values based on experience, eventually converging to the optimal Q-values and thus the optimal policy.Exploration vs. Exploitation: The Fundamental Dilemma
One of the central challenges in reinforcement learning is striking the right balance between exploration and exploitation. This is often referred to as the exploration-exploitation dilemma:
- Exploration: The agent tries new, potentially suboptimal actions to discover more about the environment and potentially find better rewards. This is crucial for discovering optimal strategies that might not be immediately obvious.
- Exploitation: The agent leverages its current knowledge to choose the action that it believes will yield the highest immediate reward based on its current value function estimates. This maximizes rewards in the short term.
If an agent only exploits, it might get stuck in a locally optimal but globally suboptimal strategy. If it only explores, it might never converge on an efficient strategy. Common strategies to manage this dilemma include ε-greedy exploration (where the agent chooses a random action with probability ε and the greedy action with probability 1-ε) and more sophisticated methods like Upper Confidence Bound (UCB) or Thompson Sampling. The balance often shifts over time, with more exploration early in training and more exploitation later on as the agent’s knowledge improves.
Discount Factor and Bellman Equation
The discount factor (γ) plays a crucial role in how an agent values future rewards relative to immediate rewards. A discount factor of 0 means the agent only cares about immediate rewards, making it very short-sighted. A discount factor of 1 means the agent values future rewards equally to immediate rewards, which can lead to infinite returns in continuing tasks and makes the problem harder to converge. Typically, γ is set to a value like 0.9 or 0.99, balancing immediate gratification with long-term strategic planning.
The Bellman Equation is a fundamental equation in dynamic programming and reinforcement learning that decomposes the value function into the immediate reward plus the discounted value of future states. For the optimal action-value function, the Bellman Optimality Equation states:
Q*(s, a) = R(s, a) + γ Σ_{s'} P(s' | s, a) max_{a'} Q*(s', a')
This equation expresses the optimal Q-value for a state-action pair as the sum of the immediate reward for taking that action, plus the discounted maximum expected future reward from the next state. The Bellman equation is central to many RL algorithms, as they often attempt to find a policy that satisfies this recursive relationship, iteratively improving value estimates until optimality is reached. Understanding these core concepts is vital for anyone looking to build or comprehend advanced reinforcement learning systems.[INLINE IMAGE 1: place after second H2 | alt=”reinforcement learning concept illustration”]
Key Algorithms and Techniques in Reinforcement Learning
The theoretical framework of MDPs and value functions gives rise to a rich diversity of algorithms designed to solve reinforcement learning problems. These algorithms can generally be categorized based on whether they explicitly learn a model of the environment (model-based) or learn directly from experience (model-free), and whether they learn value functions or directly learn policies.
Model-Free RL: Q-Learning, SARSA, and Deep Q-Networks (DQN)
Model-free algorithms are perhaps the most widely used in practical applications because they don’t require prior knowledge of the environment’s dynamics (transition probabilities and reward functions). They learn directly from observed experiences (state, action, reward, next state tuples).
- Q-Learning: As discussed, Q-learning is a prominent off-policy algorithm. “Off-policy” means that the agent learns the optimal Q-function regardless of the policy it is currently following for exploration. It’s often paired with ε-greedy exploration to balance exploring new actions with exploiting known good ones. Q-learning is guaranteed to converge to the optimal Q-values under certain conditions (e.g., discrete state/action spaces, sufficient exploration, appropriate learning rate).
- SARSA (State-Action-Reward-State-Action): SARSA is an on-policy counterpart to Q-learning. “On-policy” means the agent learns the Q-function for the policy it is currently executing, including its exploration strategy. The SARSA update rule is similar but uses the Q-value of the next action *actually taken* by the current policy, rather than the maximum possible Q-value from the next state:
Q(s, a) ← Q(s, a) + α [R + γ Q(s', a') - Q(s, a)]
Where a’ is the action chosen by the current policy in state s’. SARSA tends to be more conservative than Q-learning because it considers the consequences of its exploratory actions when learning. - Deep Q-Networks (DQN): A monumental breakthrough occurred when DeepMind combined Q-learning with deep neural networks, leading to Deep Q-Networks (DQN). In traditional Q-learning, Q-values for each state-action pair are stored in a table. This becomes intractable for environments with large or continuous state spaces (e.g., raw pixel inputs from video games). DQN uses a neural network (a “Q-network”) to approximate the Q-function, mapping states to Q-values for all possible actions. Key innovations of DQN include:
- Experience Replay: Stores past experiences (s, a, r, s’) in a replay buffer and samples mini-batches randomly from it for training. This decorrelates successive samples, addressing the problem of non-stationary data and improving training stability.
- Target Network: Uses a separate, older version of the Q-network (the “target network”) to compute the target Q-values for the update rule. This helps stabilize training by providing a more consistent target for the Q-network to learn from, reducing oscillations.
DQN famously achieved human-level performance across a range of Atari 2600 games using only raw pixel inputs, demonstrating the power of deep reinforcement learning.
Policy Gradient Methods: REINFORCE, Actor-Critic, and A2C/A3C
Instead of learning value functions, policy gradient methods directly learn a parameterized policy that maps states to actions without necessarily computing value estimates. They work by directly searching in the space of policies to find one that maximizes performance (expected return). The core idea is to estimate the gradient of the expected return with respect to the policy’s parameters and then update the parameters in the direction of this gradient.
- REINFORCE (Monte Carlo Policy Gradient): This is one of the simplest policy gradient algorithms. It works by running an entire episode, calculating the return for each state-action pair, and then updating the policy parameters using a Monte Carlo estimate of the gradient. It tends to have high variance in its gradient estimates, which can make training slow or unstable.
- Actor-Critic Methods: These methods combine the strengths of both value-based and policy-based approaches. They consist of two components:
- Actor: The policy network, which decides what action to take.
- Critic: The value function network, which evaluates the action taken by the actor. The critic’s estimate of the value (often called the “advantage function” which measures how much better an action is than the average action from that state) is used to update the actor’s policy, providing a less noisy and more stable gradient signal than REINFORCE.
This synergism helps both components learn more effectively: the actor learns better policies with the critic’s guidance, and the critic learns more accurate value functions by observing the actor’s improved behavior.
- Asynchronous Advantage Actor-Critic (A3C) and Advantage Actor-Critic (A2C): A3C was another significant innovation, allowing multiple agents to explore and learn in parallel on different instances of the environment. Each agent updates a global network asynchronously. This parallelization improves sample efficiency and stability. A2C is a synchronous, single-worker version of A3C that often performs similarly well and is easier to implement. These algorithms leverage the advantage function to reduce variance in policy updates.
Model-Based RL: Planning and Learning from World Models
Model-based reinforcement learning algorithms attempt to learn a model of the environment’s dynamics. This model predicts the next state and reward given a current state and action. Once a model is learned, the agent can use it to plan future actions without needing to interact with the real environment. This can lead to much higher sample efficiency (requiring less real-world interaction) and the ability to perform “mental simulations.”
- Learning the Model: The model itself is often a supervised learning problem, where the agent learns to predict s’ and r from (s, a) pairs collected during real interactions. This can be a neural network.
- Planning with the Model: Once a model is learned, the agent can use techniques like tree search (e.g., Monte Carlo Tree Search used in AlphaGo) or dynamic programming to plan optimal action sequences. It can simulate many possible futures within its learned model and choose the action that leads to the best simulated outcome.
- Examples: AlphaZero (a successor to AlphaGo) combined model-based planning (MCTS) with deep reinforcement learning, using a learned neural network to evaluate positions and guide the search. Recent advancements, such as “world models,” allow agents to learn compressed, predictive models of their environments and then train entirely within these imagined worlds, significantly reducing the need for real-world interactions.
Advanced Techniques: Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC)
The field of reinforcement learning is continuously evolving, with new algorithms addressing limitations of prior methods. Two prominent modern algorithms that have achieved state-of-the-art results in continuous control tasks are PPO and SAC:
- Proximal Policy Optimization (PPO): PPO is an on-policy algorithm that has become very popular due to its simplicity, robustness, and strong performance. It’s an actor-critic method that tries to take the largest possible improvement step on a policy without causing the new policy to diverge too far from the old one, which could lead to instability. It achieves this by using a clipped objective function that constrains policy updates, making it more stable than traditional policy gradient methods. PPO is widely used in OpenAI’s research and is a go-to algorithm for many continuous control tasks.
- Soft Actor-Critic (SAC): SAC is an off-policy actor-critic algorithm that aims to maximize not just the expected return but also the policy’s entropy. By maximizing entropy, the agent is encouraged to explore more and find diverse optimal policies, which can make it more robust and sample-efficient. SAC combines the stability benefits of off-policy learning (using a replay buffer) with an actor-critic structure and a unique entropy regularization term, making it highly effective for complex continuous control problems.
The progression from Q-learning to DQN, then to policy gradient methods like A3C/A2C, and finally to advanced algorithms like PPO and SAC, showcases the rapid innovation in reinforcement learning. These algorithms are the backbone of the intelligent agents driving the next wave of automation and AI capabilities across various industries.
Real-World Applications of Reinforcement Learning
The theoretical elegance and algorithmic sophistication of reinforcement learning truly come to life through its diverse and impactful real-world applications. From complex robotic movements to optimizing vast energy networks, RL is proving to be an indispensable tool for tackling problems that require adaptive, intelligent decision-making in dynamic environments.
Robotics and Autonomous Systems: From Drones to Self-Driving Cars
One of the most intuitive and visually striking applications of reinforcement learning is in robotics. Robots operating in the real world face immense complexity and uncertainty. Traditional programming struggles to account for every possible variable, making RL an ideal solution for teaching robots how to learn and adapt.
- Locomotion and Manipulation: RL has enabled robots to learn highly dexterous manipulation tasks, such as grasping irregular objects, assembling components, or even performing surgical procedures. For locomotion, RL agents can learn to walk, run, or climb in challenging terrains, often discovering gaits that are more efficient or robust than human-engineered ones. Projects involving bipedal robots, quadrupedal robots, and even soft robots have showcased RL’s ability to imbue physical systems with adaptive motor control.
- Autonomous Navigation: Self-driving cars and autonomous drones are prime examples of RL in action. These systems must make continuous, real-time decisions about speed, steering, braking, and path planning while navigating unpredictable environments. RL agents can learn to react to traffic, pedestrians, weather conditions, and unexpected obstacles, continuously optimizing for safety, efficiency, and comfort. Simulators are heavily used to train these agents, reducing the risk and cost of real-world training, with strategies then transferred to physical systems.
- Human-Robot Interaction: RL is also being explored to develop more natural and intuitive human-robot interaction, allowing robots to learn from human demonstrations or adapt their behavior based on human feedback, leading to more collaborative and effective partnerships.
Game AI: Mastering Complex Strategies (AlphaGo, Atari)
The realm of gaming has served as a powerful proving ground for reinforcement learning, demonstrating its capacity to master incredibly complex strategy games. The success of RL in this domain often highlights its ability to discover novel strategies that surpass human intuition.
- Atari Games: DeepMind’s original DQN paper famously demonstrated human-level performance across a suite of classic Atari 2600 games, learning directly from raw pixel inputs. This showed RL’s ability to handle high-dimensional observations and learn diverse control policies.
- AlphaGo and Beyond: Perhaps the most iconic achievement of RL in games is AlphaGo, developed by DeepMind. AlphaGo used deep reinforcement learning and Monte Carlo Tree Search to defeat the world champion of Go, a game far more complex than chess with an astronomical number of possible moves. Subsequent versions like AlphaZero and MuZero generalized this approach to master chess, shogi, and even arbitrary board games without any human domain knowledge, learning purely through self-play.
- Real-time Strategy (RTS) Games: OpenAI Five achieved professional-level performance in Dota 2, a highly complex real-time strategy game with a vast state space, imperfect information, and multi-agent coordination challenges. This demonstrated RL’s capabilities in multi-agent environments with long-term strategic planning.
Resource Management and Optimization: Energy Grids and Supply Chains
Beyond physical agents, reinforcement learning excels at optimizing complex systems and resource allocation, where the goal is to maximize efficiency or minimize waste over time.
- Energy Management: RL algorithms are being deployed to optimize energy consumption in large buildings, data centers, and even entire smart grids. By learning the interplay between energy demand, supply (including renewables), prices, and environmental factors, RL agents can make real-time decisions to reduce costs, enhance sustainability, and improve grid stability. For example, DeepMind used RL to reduce the energy consumed for cooling Google’s data centers by 40%.
- Supply Chain and Logistics: Managing vast and intricate supply chains involves optimizing inventory levels, routing fleets, scheduling deliveries, and responding to disruptions. RL can learn optimal policies for these tasks, dynamically adapting to changing demand, transport availability, and unforeseen events, leading to significant cost savings and improved delivery times.
- Traffic Control: RL can optimize traffic light timings and lane assignments in urban areas to alleviate congestion, reduce travel times, and improve overall traffic flow.
Personalized Recommendations and Advertising
Many online platforms leverage RL to provide highly personalized experiences, enhancing user engagement and business outcomes.
- Recommender Systems: Instead of static recommendations, RL can learn to dynamically adjust recommendations based on a user’s real-time interactions, feedback, and evolving preferences. By treating the user as the environment and the recommendations as actions, RL systems can maximize long-term engagement or satisfaction. This is particularly valuable for streaming services, e-commerce platforms, and content aggregators.
- Online Advertising: RL agents can optimize bidding strategies in real-time advertising auctions, choose which ads to display to which users, and even design ad placements, aiming to maximize click-through rates, conversions, or revenue while adhering to budget constraints.
Finance and Algorithmic Trading
The financial sector, characterized by its highly dynamic and uncertain nature, presents fertile ground for reinforcement learning applications.
- Algorithmic Trading: RL agents can learn to execute complex trading strategies, optimizing buy/sell decisions, portfolio management, and risk assessment in high-frequency trading environments. They can adapt to market fluctuations, learn from historical data, and react to real-time information to maximize returns while managing risk.
- Portfolio Optimization: RL can help in dynamically adjusting asset allocations in investment portfolios to achieve specific financial goals, taking into account market volatility and long-term trends.
- Fraud Detection: While often a supervised learning problem, RL can be used to adaptively refine fraud detection strategies, learning from the evolving tactics of fraudsters and making sequential decisions on how to investigate or block suspicious activities.
Healthcare: Drug Discovery and Treatment Personalization
The potential of reinforcement learning to revolutionize healthcare is immense, particularly in areas requiring highly individualized and adaptive approaches.
- Drug Discovery and Design: RL can accelerate the drug discovery process by autonomously navigating chemical spaces to design novel molecules with desired properties. Agents can learn to synthesize compounds, predict their efficacy, and optimize molecular structures for specific therapeutic targets, vastly reducing the time and cost associated with traditional methods.
- Personalized Treatment Plans: For chronic diseases or complex conditions, RL can help develop adaptive treatment plans. By treating a patient’s physiological state as the environment and medical interventions (medication dosage, therapy schedules) as actions, RL can learn optimal strategies to manage symptoms, prevent progression, and improve patient outcomes over time, tailoring treatment to individual responses.
- Medical Robotics: Surgical robots equipped with RL capabilities can perform precise and adaptive movements, assisting surgeons or even carrying out delicate procedures autonomously under supervision.
[INLINE IMAGE 2: place after fourth H2 | alt=”reinforcement learning comparison illustration”]
These diverse applications underscore the versatility and transformative potential of reinforcement learning across a multitude of sectors. As computational power increases and algorithms become more sophisticated, the scope for RL to solve even more complex challenges will only expand, driving innovation in autonomous systems, optimization, and intelligent decision-making across industries.
Learn more about the ethical implications of advanced AI systems.
The Synergies: Reinforcement Learning and Other AI Domains
Reinforcement learning rarely operates in isolation. Its true power often emerges when it is integrated with, or leverages techniques from, other branches of artificial intelligence. These synergies create more robust, versatile, and intelligent systems, capable of tackling even more intricate problems.
Deep Reinforcement Learning: Combining RL with Deep Learning
The most prominent and impactful synergy in modern AI is the convergence of reinforcement learning and deep learning, giving rise to Deep Reinforcement Learning (DRL). This combination has been the driving force behind many of the headline-grabbing achievements in RL over the past decade.
- Addressing High-Dimensional Data: Deep learning, particularly deep neural networks, excels at processing and extracting meaningful features from high-dimensional, raw data such as images, video, and raw sensor readings. In traditional RL, representing states and actions for such complex inputs was a major bottleneck. DRL overcomes this by using deep neural networks as function approximators for the policy and/or value functions. Instead of a tabular Q-function, a deep Q-network (DQN) maps raw pixel inputs directly to action values.
- Feature Extraction and Generalization: Deep neural networks automatically learn hierarchical representations of data. This means a DRL agent can perceive the environment directly through its raw sensory input and generalize its learned policies to unseen states, making it incredibly powerful for tasks like game playing (from pixels), robotics (from camera feeds), and autonomous driving.
- End-to-End Learning: DRL often enables end-to-end learning, where the agent learns directly from raw inputs to output actions, minimizing the need for handcrafted features or intermediate representations. This simplifies system design and allows the agent to discover optimal feature representations itself.
DQN, A3C, PPO, and SAC are all prime examples of deep reinforcement learning algorithms, demonstrating how deep learning provides the perceptual and representational capabilities that allow RL to scale to complex, real-world problems.
Imitation Learning and Inverse Reinforcement Learning
While reinforcement learning typically learns from reward signals, sometimes it’s more efficient or safer to learn from expert demonstrations, particularly when designing a reward function is difficult or dangerous.
- Imitation Learning (Learning from Demonstration): In imitation learning, an agent learns to mimic the behavior of an expert by observing demonstrations (state-action pairs). It’s essentially a supervised learning problem where the expert’s actions are treated as labels. This is useful for bootstrapping RL agents, allowing them to learn basic skills quickly before refining them with RL, or for tasks where designing a reward function is hard (e.g., driving, intricate manipulation). Behavioral cloning is a common form of imitation learning.
- Inverse Reinforcement Learning (IRL): IRL takes the opposite approach. Instead of learning a policy from a reward function, IRL infers the underlying reward function that explains an expert’s observed behavior. This is incredibly powerful because it can solve the “reward engineering problem” – the challenge of designing effective reward functions for complex tasks. Once a reward function is learned from expert demonstrations, a standard RL algorithm can then be used to find an optimal policy, potentially even surpassing the expert’s performance. For example, in autonomous driving, IRL could infer a reward function that balances safety, speed, and comfort by observing human drivers, rather than explicitly programming these trade-offs.
Reinforcement Learning in Generative AI and Large Language Models
The recent explosion of generative AI, particularly large language models (LLMs), has created new avenues for reinforcement learning. RL is playing a critical role in refining and aligning these powerful models.
- Reinforcement Learning from Human Feedback (RLHF): This technique has been instrumental in the success of models like ChatGPT. LLMs initially generate text based on predicting the next token. However, their raw output might be unhelpful, biased, or even harmful. RLHF uses human preferences to train a “reward model,” which then provides feedback to the LLM. The LLM then fine-tunes its generation policy using reinforcement learning (e.g., PPO) to produce outputs that are aligned with human values, helpfulness, and safety criteria. This is a powerful way to guide complex generative models towards desired behaviors without explicit programming for every possible output.
- Controlling Generative Processes: RL can also be used to control the generation process itself in other generative models, such as image generation, to ensure that the generated content meets specific criteria or constraints, or to explore latent spaces more effectively.
Explainable Reinforcement Learning (XRL): Towards Transparency
As RL systems become more autonomous and are deployed in critical applications, understanding their decision-making process becomes paramount. This gives rise to Explainable Reinforcement Learning (XRL), a field that borrows techniques from Explainable AI (XAI).
- Understanding Policy Decisions: XRL aims to provide insights into why an RL agent takes certain actions in particular states. This can involve visualizing the agent’s attention, analyzing feature importance in the neural networks, or extracting simpler, human-interpretable policies from complex learned ones.
- Debugging and Trust: Explanations are crucial for debugging agent failures, building trust with human users, and ensuring ethical and fair behavior, especially in high-stakes domains like healthcare or finance. Methods include saliency maps, causal explanations, and counterfactual reasoning.
These interconnections demonstrate that reinforcement learning is not an isolated discipline but a dynamically interacting component within the broader AI landscape. Its ability to learn from interaction and optimize for long-term goals makes it a powerful partner for other AI technologies, collectively pushing the boundaries of what intelligent systems can achieve in 2026 and beyond.
Challenges and Limitations of Reinforcement Learning
Despite its remarkable successes and transformative potential, reinforcement learning is not without its significant challenges and limitations. Addressing these issues is a key focus of ongoing research and development, particularly as we push RL towards more complex, real-world deployments.
Sample Efficiency and Data Requirements
One of the most frequently cited limitations of reinforcement learning is its often-prohibitive demand for data or interaction time with the environment.
- High Number of Interactions: RL agents typically require a vast number of trials and errors to learn optimal policies. For physical robots, this translates to expensive and time-consuming real-world interaction, leading to wear and tear. In simulations, even though interactions are cheaper, the sheer volume can still demand substantial computational resources and time.
- Difficulty in Real-World Application: While games like Atari and Go provide convenient, fast-resetting environments, applying RL to real-world tasks like autonomous driving or complex robotics often means a single “episode” can last hours, and collecting enough diverse experience is incredibly challenging and often impractical.
- Contrast with Supervised Learning: Unlike supervised learning, where a single labeled example can teach a feature, in RL, an agent might need to explore many different scenarios to understand the consequences of its actions.
Researchers are actively working on solutions like model-based RL (learning an internal model of the environment to simulate experiences), offline RL (learning from pre-collected, static datasets), and transfer learning (applying knowledge from one task/environment to another) to improve sample efficiency.
The Curse of Dimensionality
The “curse of dimensionality” refers to how exponentially the volume of space (and thus the number of samples needed) increases as the number of dimensions (states or actions) grows. This problem plagues reinforcement learning:
- Large State Spaces: If an environment has many observable variables, or if the state is represented by raw sensory input (like high-resolution images or videos), the number of possible states becomes astronomically large. Tabular methods (like basic Q-learning) are simply infeasible.
- Continuous State/Action Spaces: Many real-world problems involve continuous states (e.g., a robot’s joint angles, vehicle speed) and continuous actions (e.g., steering angle, motor torque). Discretizing these spaces can lead



