
What is a Transformer Model? Unpacking AI’s Generative Revolution
Affiliate disclosure: This article may contain affiliate links. Recommendations are independent and editorially driven.
In the rapidly accelerating landscape of artificial intelligence, certain innovations stand as monumental turning points, fundamentally reshaping what’s possible and dictating the trajectory of future advancements. Among these, the Transformer model reigns supreme, a revolutionary neural network architecture that has not only redefined the capabilities of natural language processing (NLP) but has also extended its profound influence across virtually every domain of AI, from computer vision to drug discovery and robotics.
Before the advent of the Transformer in 2017, the prevailing architectures for sequence processing – a critical task for understanding language – were recurrent neural networks (RNNs) and their more sophisticated variants like Long Short-Term Memory (LSTM) networks. While powerful for their time, these models were inherently sequential, processing data word by word. This bottleneck severely limited their ability to handle long-range dependencies efficiently, parallelize computations, and scale to the massive datasets and model sizes we see today. The Transformer model, introduced in the seminal paper “Attention Is All You Need,” offered a radical departure, entirely discarding recurrence and convolutions in favor of a mechanism known as “self-attention.” This innovation unlocked unprecedented performance, scalability, and an almost poetic understanding of context within vast swathes of data.
Today, in 2026, the term “Transformer model” is synonymous with the cutting edge of AI, underpinning the colossal large language models (LLMs) like GPT-4 and its successors, advanced translation systems, sophisticated code generators, and even groundbreaking image synthesis tools. Its elegance lies in its ability to simultaneously consider all parts of an input sequence, weighing the importance of different words or data points relative to each other, a feat that mimics human-like contextual understanding. This article will meticulously unpack what a Transformer model is, delve into its intricate architecture, explore the foundational self-attention mechanism, highlight its myriad applications, discuss its impact, and look ahead at the future evolution of this transformative technology.
The Dawn of a New Era: Understanding the Core of the Transformer Model
To grasp the significance of the Transformer, one must first understand the landscape it emerged from. For decades, the processing of sequential data – be it words in a sentence, frames in a video, or nucleotides in a DNA strand – was dominated by models that processed information one step at a time. This sequential nature, while intuitive, presented significant limitations. The Transformer model broke free from these constraints, introducing a paradigm shift that prioritized parallel processing and a sophisticated mechanism for contextual understanding.
From RNNs to Transformers: A Paradigm Shift
Prior to the Transformer, recurrent neural networks (RNNs) and their derivatives, LSTMs and Gated Recurrent Units (GRUs), were the workhorses for sequence modeling. These models process elements of a sequence one after another, maintaining a “hidden state” that attempts to encapsulate information from previous steps. While this allowed them to capture some temporal dependencies, they suffered from several critical drawbacks:
- Vanishing/Exploding Gradients: Over long sequences, the influence of early elements would often fade (vanishing gradients) or become excessively amplified (exploding gradients), making it difficult to learn long-range dependencies effectively.
- Lack of Parallelization: The inherent sequential processing meant that each step had to wait for the previous one to complete. This severely hampered training speed on modern parallel computing hardware like GPUs, especially with very long sequences.
- Fixed-Size Context: The hidden state, despite improvements in LSTMs, still represented a fixed-size bottleneck for information from potentially very long input sequences.
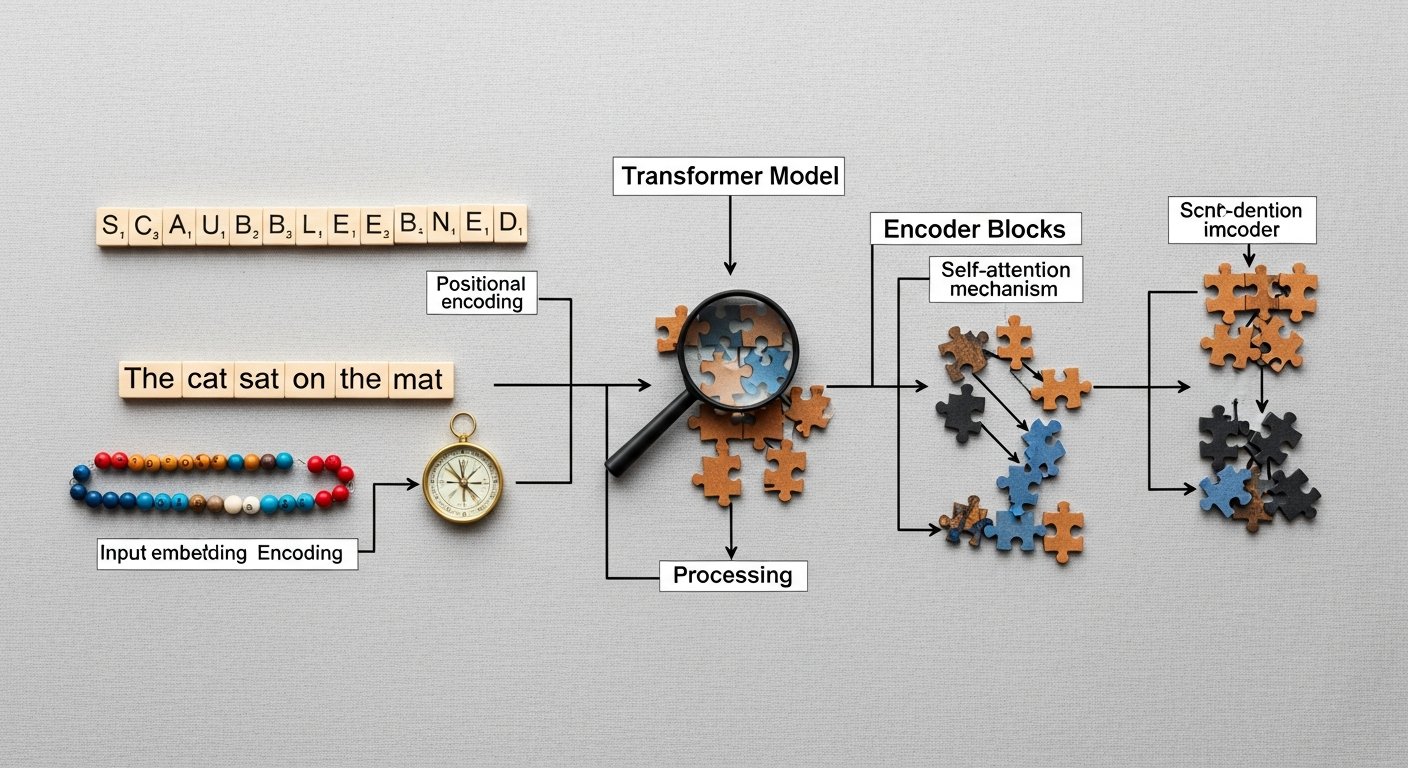
The Transformer model fundamentally addresses these issues by abandoning recurrence. Instead of processing tokens sequentially, it processes all tokens in a sequence simultaneously. This parallelism is a game-changer, dramatically accelerating training times and allowing models to scale to unprecedented sizes and datasets. But how does it maintain sequential information without recurrence? The answer lies in its unique architecture, primarily driven by the self-attention mechanism and positional encodings.
The Core Idea: Parallel Processing and Attention
At its heart, the Transformer model posits that the critical ingredient for understanding sequences isn’t sequential processing, but rather the ability to weigh the relevance of different parts of the input to each other, regardless of their position. This is achieved through the “attention mechanism.” Specifically, the Transformer employs “self-attention,” which allows each element in an input sequence to “attend” to all other elements in the same sequence, identifying which elements are most relevant for processing the current element. Imagine reading a sentence: “The quick brown fox jumped over the lazy dog.” When you process the word “jumped,” your brain implicitly connects it to “fox” (the subject) and “dog” (the object) to understand the action. The self-attention mechanism computationally mimics this selective focus.
By processing all inputs in parallel and using self-attention to establish intricate relationships between tokens, the Transformer model achieves several profound advantages:
- Unlimited Context Window: Unlike RNNs with their limited hidden states, self-attention can directly connect any two words in a sequence, no matter how far apart, allowing it to capture true long-range dependencies.
- High Parallelizability: The absence of recurrence means that computations for different parts of the sequence can be performed simultaneously, leading to significantly faster training on GPUs and TPUs.
- Reduced Sequential Dependencies: Information flow is no longer strictly left-to-right; any token can instantly access information from any other token.
This foundational shift enabled the construction of models that could learn far more complex patterns and relationships within data, laying the groundwork for the extraordinary capabilities we witness in modern AI.
[INLINE IMAGE 1: place after second H2 | alt=”what is a transformer model concept illustration”]
Deconstructing the Transformer Architecture: Key Components Explained
The magic of the Transformer model lies in its elegant yet intricate architecture. While it eschews recurrence and convolution, it’s a sophisticated ensemble of several interconnected components, each playing a crucial role in its ability to process and generate sequences. Understanding these components is key to appreciating the model’s power.
At a high level, the original Transformer consists of an encoder stack and a decoder stack. The encoder processes the input sequence, building a rich contextual representation, while the decoder uses this representation to generate an output sequence, typically in a different language or format. Both stacks are composed of multiple identical layers.
The Encoder Stack: Processing Input Sequences
The encoder’s primary role is to take an input sequence (e.g., a sentence in English) and transform it into a sequence of continuous representations, or vectors, that capture the meaning and context of each word (or token) within the sentence. It consists of a stack of identical encoder layers. Each encoder layer has two main sub-layers:
- Multi-Head Self-Attention Mechanism: This is the core innovation. It allows the model to weigh the importance of all other words in the input sentence when processing a particular word. Instead of a single “attention head,” the Transformer uses multiple heads in parallel, each focusing on different aspects of the relationships between words. This diverse perspective enriches the contextual understanding.
- Position-wise Feed-Forward Network: A simple fully connected neural network applied independently and identically to each position (word) in the sequence. It acts as a processing step after attention, allowing the model to further transform the representations based on the information gathered by the attention mechanism.
Crucially, each sub-layer is augmented with a residual connection (adding the input of the sub-layer to its output) and layer normalization. Residual connections help with training very deep networks by allowing gradients to flow more easily, preventing vanishing gradients. Layer normalization stabilizes training by normalizing the activations across the features for each sample independently.
The Decoder Stack: Generating Output Sequences
The decoder stack, also composed of multiple identical layers, is responsible for generating the output sequence (e.g., the translated sentence in French) one token at a time, based on the contextual representations produced by the encoder. Each decoder layer has three main sub-layers:
- Masked Multi-Head Self-Attention: Similar to the encoder’s self-attention, but with a critical difference: it’s “masked.” This masking ensures that when predicting the next word, the decoder can only attend to words that have already been generated (or are to its left in the sequence) and not future words. This prevents the model from “cheating” by looking at the answer it’s trying to predict.
- Multi-Head Encoder-Decoder Attention: This sub-layer performs attention over the output of the encoder stack. It allows the decoder to focus on relevant parts of the input sequence while generating the output. This is where the communication between the encoder’s understanding of the input and the decoder’s generation of the output occurs.
- Position-wise Feed-Forward Network: Identical to the one in the encoder, it further processes the combined information from the two attention layers.
Like the encoder, each sub-layer in the decoder also employs residual connections and layer normalization. The output of the final decoder layer then passes through a linear layer and a softmax function to produce the probability distribution over the vocabulary for the next predicted token.
Multi-Head Self-Attention: The Brain of the Transformer
The self-attention mechanism is arguably the most brilliant and innovative component of the Transformer model. It enables the model to draw connections between different positions in a sequence to compute a representation for each position. For instance, in the sentence “The animal didn’t cross the street because it was too tired,” self-attention helps the model understand that “it” refers to “animal.”
Here’s how it generally works:
- Query, Key, Value (QKV): For each token in the input sequence, three vectors are generated: a Query (Q), a Key (K), and a Value (V). These are learned transformations of the token’s embedding.
- Calculating Attention Scores: To determine how much each word should “attend” to others, the Query vector of the current word is dot-producted with the Key vectors of all other words in the sequence. This produces a raw “attention score.”
- Scaling and Softmax: These raw scores are then scaled (to prevent very large values from dominating) and passed through a softmax function. Softmax normalizes the scores into a probability distribution, indicating how much “attention” each other word should get.
- Weighted Sum of Values: Finally, these attention probabilities are multiplied by the Value vectors of the corresponding words and summed up. The result is a new vector for the current word that is a weighted average of the Value vectors of all words in the sequence, with the weights determined by the attention scores. This new vector now incorporates contextual information from the entire sequence.
The “Multi-Head” aspect means that this attention process is performed multiple times in parallel, using different sets of learned Q, K, V matrices. Each “head” learns to focus on different types of relationships or different parts of the context. The outputs from these multiple heads are then concatenated and linearly transformed, providing a richer and more nuanced contextual representation.
Positional Encoding: Preserving Sequence Order
Since the Transformer processes all words in parallel and lacks recurrence, it has no inherent understanding of the order of words in a sequence. Without this, “dog bites man” would be indistinguishable from “man bites dog.” To remedy this, the Transformer injects “positional encodings” into the input embeddings. These are vectors that carry information about the absolute or relative position of each token in the sequence. These encodings are added to the input embeddings at the very beginning of the encoder and decoder stacks. They typically consist of sine and cosine functions of different frequencies, allowing the model to easily learn and generalize to longer sequences than those seen during training.
Feed-Forward Networks and Residual Connections
Beyond the attention mechanisms, each encoder and decoder layer includes a simple, fully connected feed-forward network. This network is applied independently to each position (token) and consists of two linear transformations with a ReLU activation in between. It serves to further process the representations produced by the attention layers, adding non-linearity and allowing the model to learn more complex patterns. As mentioned, residual connections and layer normalization are critical features throughout the architecture, providing stability and facilitating the training of very deep Transformer models by allowing gradients to flow more smoothly through the network.
Why Transformers Became a Game-Changer: Unpacking Their Advantages
The architectural innovations of the Transformer model translated into a cascade of practical advantages that rapidly cemented its status as the foundational architecture for modern AI. Its impact was not merely incremental but represented a qualitative leap in capabilities, particularly for tasks involving sequential data.
Eliminating Recurrence: Speed and Scalability
The most immediate and impactful advantage of the Transformer’s design is its complete abandonment of recurrence. RNNs, by their nature, must process tokens sequentially. If you have a sentence of 100 words, the 100th word’s processing cannot begin until the 99th word is done. This creates a bottleneck that prevents parallel computation. In contrast, the Transformer processes all input tokens simultaneously. This parallelism allows for:
- Faster Training: Modern computing hardware, especially GPUs and TPUs, is optimized for parallel operations. By allowing computations across the entire sequence to happen at once, Transformers can be trained significantly faster than RNNs, reducing training times from weeks to days or even hours for massive datasets.
- Scalability to Enormous Datasets: The ability to train faster means that Transformers can leverage vastly larger datasets. This access to more data, combined with their capacity to learn complex patterns, is a key reason behind the incredible performance of modern large language models.
- Handling Longer Sequences: While RNNs struggled with “long-term dependencies” due to vanishing gradients over extended sequences, Transformers can theoretically process sequences of arbitrary length because any word can directly attend to any other word, regardless of their distance. This provides a much more robust mechanism for capturing context over long passages of text or other sequential data.
Capturing Context: The Power of Self-Attention
The self-attention mechanism is the true intellectual core of the Transformer’s success. It allows the model to dynamically weigh the importance of every other token in the input sequence when processing a given token. This is a far more nuanced and powerful way of understanding context compared to the fixed-size hidden states of RNNs. Consider the ambiguity of words like “bank” (river bank vs. financial institution). Self-attention allows the model to look at surrounding words (“river,” “money”) and assign higher relevance to the correct contextual clues, resolving the ambiguity directly.
Key benefits of self-attention include:
- Global Contextual Understanding: Every token’s representation is influenced by every other token, creating a truly global contextual understanding rather than a localized one.
- Dynamic Weighting: The relevance weights are not fixed but learned dynamically for each input sequence, adapting to the specific context.
- Interpretability (to an extent): While deep learning models are often “black boxes,” the attention weights can sometimes offer insights into which parts of the input the model focused on when making a decision, providing a degree of explainability.
Versatility and Transfer Learning Capabilities
The Transformer’s architecture proved remarkably versatile. Its ability to learn rich, contextual embeddings from vast amounts of unlabeled data, combined with its parallelizability, made it perfectly suited for the paradigm of “pre-training and fine-tuning.”
- Pre-training: A large Transformer model can be pre-trained on a massive corpus of text (e.g., the entire internet) using self-supervised tasks (like predicting masked words or the next sentence). During this phase, the model learns a deep understanding of language structure, grammar, semantics, and even some world knowledge without explicit labels.
- Fine-tuning: Once pre-trained, this highly knowledgeable model can then be fine-tuned on smaller, task-specific labeled datasets (e.g., sentiment analysis, question answering). The pre-trained knowledge acts as a powerful starting point, requiring far less task-specific data and achieving significantly better performance than training a model from scratch.
This transfer learning paradigm, pioneered by models like BERT and GPT, unlocked unprecedented performance across a multitude of NLP tasks and became a blueprint for much of modern AI development. The same principles have since been extended to computer vision (Vision Transformers), audio, and multimodal tasks, showcasing the architecture’s inherent adaptability.
The combination of these advantages – unparalleled speed, global contextual awareness, and transferability – fundamentally shifted the landscape of AI research and application, paving the way for the sophisticated and intelligent systems we interact with today.
[INLINE IMAGE 2: place after fourth H2 | alt=”what is a transformer model comparison illustration”]
Key Applications and Impact Across Industries
The theoretical elegance and practical advantages of the Transformer model quickly translated into revolutionary advancements across a multitude of domains. Its impact has been so profound that it’s difficult to find an area of AI development that hasn’t been touched or transformed by this architecture. In 2026, Transformers are not just academic curiosities; they are integral to the products and services that define our digital world.
Revolutionizing Natural Language Processing (LLMs, Translation, Summarization)
NLP was the original proving ground for the Transformer, and it remains its most prominent application area. The ability to model long-range dependencies and capture nuanced context has led to breakthroughs that were previously unimaginable:
- Large Language Models (LLMs): This is arguably the most impactful application. Models like OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, and countless others are all built on the Transformer architecture. These LLMs can generate coherent, contextually relevant, and even creative text, perform complex reasoning, answer questions, write code, and engage in sophisticated conversations. They power advanced chatbots, virtual assistants, content creation tools, and educational platforms.
- Machine Translation: Transformer models have drastically improved the quality and fluency of machine translation. Google Translate and similar services leverage Transformers to provide near real-time, highly accurate translations across dozens of languages, understanding grammatical structures and semantic nuances far better than previous systems.
- Text Summarization: From condensing lengthy research papers to summarizing news articles, Transformers excel at generating concise and accurate summaries, extracting key information while preserving meaning.
- Sentiment Analysis & Text Classification: Transformers can accurately discern the emotional tone of text or categorize it into predefined topics, crucial for customer service, market research, and content moderation.
- Question Answering: These models can read a passage of text and answer complex questions based on the information contained within, demonstrating a deep comprehension of the content.
- Code Generation and Completion: Specialized Transformer models like GitHub Copilot can assist developers by generating code snippets, completing lines, or even translating natural language descriptions into functional code, dramatically boosting productivity.
Beyond Text: Transformers in Computer Vision
While initially designed for sequences of text, researchers soon realized the Transformer’s self-attention mechanism could be applied to other forms of sequential or structured data, including images. Images can be broken down into sequences of “patches” or tokens, allowing Transformers to process them. This led to the emergence of Vision Transformers (ViTs) and their successors, challenging the long-standing dominance of Convolutional Neural Networks (CNNs) in computer vision:
- Image Classification: ViTs have achieved state-of-the-art results on image classification benchmarks, demonstrating their ability to capture global relationships between different parts of an image.
- Object Detection & Segmentation: Advanced Transformer-based models are used for identifying and localizing objects within images and videos, and even segmenting them precisely, critical for autonomous vehicles, medical imaging, and surveillance.
- Image Generation & Editing: Models like DALL-E, Stable Diffusion, and Midjourney, which generate photorealistic images from text prompts, are potent examples of Transformers’ multimodal capabilities. They bridge language understanding with image synthesis.
- Video Understanding: By treating video frames as sequences, Transformers can analyze actions, events, and spatial-temporal relationships in videos, vital for content analysis, sports analytics, and security.
Expanding Horizons: Audio, Robotics, and Scientific Discovery
The versatility of the Transformer architecture means its influence continues to expand into unexpected areas:
- Audio Processing: Transformers are increasingly used for speech recognition, speaker identification, and even music generation, treating audio signals as sequences of features.
- Robotics: In robotics, Transformers can process sensor data, plan complex action sequences, and even learn dexterous manipulation tasks, often in conjunction with reinforcement learning. They help robots understand human commands and interact with dynamic environments.
- Drug Discovery and Materials Science: By modeling sequences of molecules, proteins, or genetic code, Transformers are accelerating drug design, predicting protein structures (e.g., AlphaFold’s success heavily relies on Transformer-like attention mechanisms), and discovering new materials properties. They can learn the complex relationships between molecular structure and function.
- Financial Forecasting: In some experimental applications, Transformers are used to analyze time-series data, such as stock prices or economic indicators, to identify patterns and make predictions.
The profound impact of the Transformer model is not just about incremental improvements; it’s about enabling entirely new paradigms of AI functionality. Its ability to learn complex, long-range dependencies across diverse data types makes it a cornerstone technology for the future of intelligent systems, driving innovation across nearly every industry.
The Ecosystem of Transformer Models: Major Architectures and Variants
The original “Attention Is All You Need” paper laid the foundational architecture, but the field quickly diversified. Researchers adapted, optimized, and extended the Transformer, leading to a vibrant ecosystem of specialized models, each excelling in particular tasks or possessing unique characteristics. Understanding these variants is crucial for appreciating the breadth of Transformer capabilities.
Encoder-Only Models: Understanding Context (e.g., BERT, RoBERTa)
These models utilize only the encoder stack of the Transformer architecture. Their primary purpose is to generate rich, contextualized embeddings for input sequences. They are typically pre-trained on massive text corpora using self-supervised objectives, such as predicting masked words (Masked Language Model – MLM) or identifying if two sentences follow each other (Next Sentence Prediction – NSP).
- BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, BERT was a landmark model. Its key innovation was bidirectional pre-training, meaning it considered context from both the left and right of a word simultaneously. This allowed it to achieve a deeper understanding of language than previous unidirectional models. BERT is excellent for tasks requiring a deep understanding of input text, such as sentiment analysis, question answering (where it can identify the exact span of text that answers a query), and text classification.
- RoBERTa (Robustly Optimized BERT Approach): A refinement of BERT by Facebook AI, which showed that BERT’s performance could be significantly improved by training it longer, on more data, with larger batch sizes, and by dynamically masking tokens. It demonstrated that simply optimizing training procedures could yield substantial gains.
- DistilBERT: A smaller, faster, and lighter version of BERT, developed by Hugging Face. It retains much of BERT’s performance while being more efficient, suitable for deployment in resource-constrained environments.
Encoder-only models are typically fine-tuned for specific “understanding” tasks by adding a small task-specific layer on top of their contextual embeddings.
Decoder-Only Models: Generative Powerhouses (e.g., GPT series, LLaMA)
These models leverage only the decoder stack of the Transformer, often without the encoder-decoder attention mechanism (as there’s no encoder output to attend to). Their strength lies in text generation. They are usually pre-trained as unidirectional language models, meaning they predict the next word in a sequence based on all preceding words.
- GPT (Generative Pre-trained Transformer) Series: Developed by OpenAI, these models are arguably the most famous examples of decoder-only Transformers. From GPT-1 to GPT-4 and beyond, they demonstrate incredible capabilities in generating coherent, creative, and contextually appropriate text. Their primary pre-training objective is next-token prediction. They excel at tasks like creative writing, dialogue generation, summarization, and even reasoning by formulating problems as text generation tasks.
- LLaMA (Large Language Model Meta AI) & LLaMA 2: Developed by Meta AI, the LLaMA family of models became highly influential due to their open-source nature (for research and commercial use, respectively), enabling widespread innovation and the development of countless derivative models (e.g., Alpaca, Vicuna). They showcase that competitive performance can be achieved with smaller, more efficient models when trained on vast datasets.
- Mistral AI Models (e.g., Mistral 7B, Mixtral 8x7B): Emerging players that have demonstrated exceptional performance for their size, often leveraging advanced techniques like Grouped-Query Attention and Mixture-of-Experts (MoE) architectures to achieve high efficiency and quality.
Decoder-only models are the backbone of most generative AI applications, from sophisticated chatbots to content creation engines.
Encoder-Decoder Models: Translation and Sequence-to-Sequence (e.g., T5, BART)
These models employ both the encoder and decoder stacks, faithfully following the original Transformer architecture. They are ideal for “sequence-to-sequence” tasks where an input sequence is transformed into a potentially different output sequence.
- T5 (Text-to-Text Transfer Transformer): Developed by Google, T5’s core idea is to frame *every* NLP problem as a “text-to-text” task. Whether it’s translation, summarization, question answering, or classification, the input is text, and the output is text. This unified approach simplified task design and showed strong performance across a wide range of benchmarks.
- BART (Bidirectional and Auto-Regressive Transformers): Developed by Facebook AI, BART combines the pre-training objectives of BERT (masking tokens) with a GPT-like generative objective (auto-regressive decoding). It’s particularly strong for tasks requiring both understanding and generation, such as summarization and text generation.
These models are particularly effective for tasks like machine translation, abstractive summarization (where the summary might include new words not in the original text), and other complex transformations of text.
Vision Transformers (ViT) and Their Innovations
The application of Transformers to computer vision marked a significant cross-domain transfer of technology. Vision Transformers treat images not as a grid of pixels but as a sequence of image “patches.”
- Vision Transformer (ViT): Introduced by Google, ViT was the first model to successfully apply the pure Transformer architecture directly to image classification. It divides an image into fixed-size patches, linearly embeds them, adds positional encodings, and feeds them to a standard Transformer encoder. It demonstrated that Transformers could outperform CNNs on large datasets, especially when pre-trained on massive amounts of image data.
- Swin Transformer: Addresses the computational cost of ViTs for high-resolution images by introducing “shifted windows.” Instead of global self-attention across the entire image, Swin Transformers compute self-attention within local windows and then shift these windows in successive layers, allowing for cross-window connections and hierarchical feature learning, making them more efficient and suitable for dense prediction tasks like object detection and segmentation.
- DALL-E, Stable Diffusion, Midjourney: While not pure ViTs, these multimodal generative models often incorporate Transformer or attention-based components (e.g., in their U-Net backbones or text encoders) to bridge the gap between text prompts and image generation, representing a powerful synthesis of vision and language understanding.
Other Noteworthy Variants and Specialized Architectures
The rapid pace of innovation has led to countless other specialized Transformer models:
- Sparse Transformers: Address the quadratic complexity of self-attention (where attention scales with the square of the sequence length) by allowing each token to attend only to a subset of other tokens, making them more efficient for very long sequences.
- Long-Context Transformers (e.g., Longformer, BigBird, Perceiver IO): Focus on enabling Transformers to handle extremely long sequences (e.g., entire books, long codebases) by using various forms of sparse attention or by re-framing the attention mechanism to scale more efficiently.
- Mixture-of-Experts (MoE) Models: These models incorporate multiple “expert” neural networks within their layers. During inference, a “router” mechanism selects which expert (or combination of experts) to use for processing a given input token, allowing the model to have billions of parameters while only activating a fraction of them for any given input, leading to higher efficiency and specialized knowledge. Google’s Switch Transformer and Mistral’s Mixtral are prominent examples.
This dynamic ecosystem showcases the Transformer’s adaptability and the relentless pursuit of more efficient, powerful, and specialized AI models. As research continues, we can expect even more innovative variants to emerge, pushing the boundaries of what these architectures can achieve.
| Model Family | Architecture Type | Primary Use Cases | Key Innovation / Characteristics |
|---|---|---|---|
| BERT / RoBERTa | Encoder-Only | Text classification, Question Answering, Sentiment Analysis, Named Entity Recognition | Bidirectional pre-training (Masked Language Model, Next Sentence Prediction), deep contextual understanding. |
| GPT Series (e.g., GPT-3, GPT-4) | Decoder-Only | Text generation, Conversational AI, Creative writing, Code generation, Summarization | Unidirectional (auto-regressive) pre-training, massive scale, emergent few-shot learning capabilities. |
| T5 / BART | Encoder-Decoder | Machine Translation, Abstractive Summarization, Text-to-Text conversion for various tasks | Unified text-to-text framework (T5), combined denoising/generative pre-training (BART), versatile for sequence-to-sequence. |
| Vision Transformer (ViT) / Swin | Encoder (applied to image patches) | Image Classification, Object Detection, Image Segmentation | Applying pure Transformer to vision by treating image patches as tokens (ViT); hierarchical attention with shifted windows for efficiency (Swin). |
| LLaMA / Mistral (MoE) | Decoder-Only (often) | General-purpose LLM, chat, coding, instruction following | Focus on efficiency, open-source accessibility (LLaMA); Mixture-of-Experts for high performance at lower inference cost (Mixtral). |
Challenges and Limitations of Transformer Models
Despite their unparalleled success and transformative impact, Transformer models are not without their limitations and challenges. As their scale and deployment continue to grow in 2026, understanding these drawbacks becomes increasingly critical for responsible development and realistic application.
The Scale Problem: Computational Demands and Energy Footprint
One of the most significant challenges associated with Transformer models is their insatiable appetite for computational resources. The fundamental self-attention mechanism, while powerful, scales quadratically with the length of the input sequence. This means that if you double the length of a sequence, the computational cost of attention quadruples. For very long documents, this quickly becomes prohibitive.
- High Training Costs: Training the largest Transformer models (like GPT-4 or Gemini) requires vast amounts of computing power, consuming millions of dollars in electricity and thousands of GPU-hours. This creates a high barrier to entry for smaller organizations and researchers, centralizing AI development among a few tech giants.
- High Inference Costs: Even after training, running these models for inference (making predictions or generating text) can be computationally intensive, leading to significant operational costs, especially for real-time applications.
- Environmental Impact: The enormous energy consumption associated with training and deploying these models raises serious environmental concerns, contributing to carbon emissions. Researchers are actively working on “green AI” solutions to mitigate this.
- Memory Constraints: The attention mechanism also demands significant memory to store the attention weights and intermediate activations, further limiting the maximum sequence length that can be processed on available hardware.
While innovations like sparse attention, linear attention, and Mixture-of-Experts (MoE) architectures are attempting to alleviate these issues, the fundamental scaling properties remain a significant hurdle for extremely long contexts or ubiquitous edge deployment.
Data Dependency and the “Garbage In, Garbage Out” Dilemma
Transformer models, especially large language models, are incredibly data-hungry. Their impressive capabilities stem from being trained on vast amounts of text and other data, often scraped from the internet. This reliance on massive datasets introduces several problems:
- Quality of Data: The internet is full of noisy, biased, and often incorrect information. If the training data contains these flaws, the model will learn and replicate them. This is the “garbage in, garbage out” problem on a grand scale.
- Bias Amplification: Societal biases present in the training data (e.g., gender stereotypes, racial prejudices, political leanings) are absorbed and amplified by the model, potentially leading to unfair, discriminatory, or harmful outputs.
- Hallucination: Even with vast data, models can sometimes generate plausible-sounding but entirely fabricated information or make logical errors. They learn patterns and statistics from data, not necessarily deep factual understanding or common sense.
- Out-of-Distribution Data: Transformers perform best on data similar to their training distribution. When confronted with novel or significantly different data, their performance can degrade gracefully or catastrophically.
Curating, filtering, and cleaning such colossal datasets is an immense challenge, and ensuring data quality and ethical sourcing is an ongoing, complex task for the AI community.
Interpretability and Explainability: A Black Box Conundrum
Like many deep neural networks, Transformer models are largely “black boxes.” It’s difficult to understand precisely *why* a model makes a particular decision or generates a specific output. While attention weights can offer some hints about which parts of the input were important, they don’t provide a complete causal explanation. This lack of interpretability poses problems for:
- Trust and Reliability: In critical applications (e.g., medical diagnosis, legal advice, autonomous systems), being able to explain a decision is paramount for trust, accountability, and
What is a Transformer Model? Unpacking AI’s Generative Revolution
Affiliate disclosure: This article may contain affiliate links. Recommendations are independent and editorially driven.
In the rapidly accelerating landscape of artificial intelligence, certain innovations stand as monumental turning points, fundamentally reshaping what’s possible and dictating the trajectory of future advancements. Among these, the Transformer model reigns supreme, a revolutionary neural network architecture that has not only redefined the capabilities of natural language processing (NLP) but has also extended its profound influence across virtually every domain of AI, from computer vision to drug discovery and robotics.
Before the advent of the Transformer in 2017, the prevailing architectures for sequence processing – a critical task for understanding language – were recurrent neural networks (RNNs) and their more sophisticated variants like Long Short-Term Memory (LSTM) networks. While powerful for their time, these models were inherently sequential, processing data word by word. This bottleneck severely limited their ability to handle long-range dependencies efficiently, parallelize computations, and scale to the massive datasets and model sizes we see today. The Transformer model, introduced in the seminal paper “Attention Is All You Need,” offered a radical departure, entirely discarding recurrence and convolutions in favor of a mechanism known as “self-attention.” This innovation unlocked unprecedented performance, scalability, and an almost poetic understanding of context within vast swathes of data.
Today, in 2026, the term “Transformer model” is synonymous with the cutting edge of AI, underpinning the colossal large language models (LLMs) like GPT-4 and its successors, advanced translation systems, sophisticated code generators, and even groundbreaking image synthesis tools. Its elegance lies in its ability to simultaneously consider all parts of an input sequence, weighing the importance of different words or data points relative to each other, a feat that mimics human-like contextual understanding. This article will meticulously unpack what a Transformer model is, delve into its intricate architecture, explore the foundational self-attention mechanism, highlight its myriad applications, discuss its impact, and look ahead at the future evolution of this transformative technology.
The Dawn of a New Era: Understanding the Core of the Transformer Model
To grasp the significance of the Transformer, one must first understand the landscape it emerged from. For decades, the processing of sequential data – be it words in a sentence, frames in a video, or nucleotides in a DNA strand – was dominated by models that processed information one step at a time. This sequential nature, while intuitive, presented significant limitations. The Transformer model broke free from these constraints, introducing a paradigm shift that prioritized parallel processing and a sophisticated mechanism for contextual understanding.
From RNNs to Transformers: A Paradigm Shift
Prior to the Transformer, recurrent neural networks (RNNs) and their derivatives, LSTMs and Gated Recurrent Units (GRUs), were the workhorses for sequence modeling. These models process elements of a sequence one after another, maintaining a “hidden state” that attempts to encapsulate information from previous steps. While this allowed them to capture some temporal dependencies, they suffered from several critical drawbacks:
- Vanishing/Exploding Gradients: Over long sequences, the influence of early elements would often fade (vanishing gradients) or become excessively amplified (exploding gradients), making it difficult to learn long-range dependencies effectively.
- Lack of Parallelization: The inherent sequential processing meant that each step had to wait for the previous one to complete. This severely hampered training speed on modern parallel computing hardware like GPUs, especially with very long sequences.
- Fixed-Size Context: The hidden state, despite improvements in LSTMs, still represented a fixed-size bottleneck for information from potentially very long input sequences.
The Transformer model fundamentally addresses these issues by abandoning recurrence. Instead of processing tokens sequentially, it processes all tokens in a sequence simultaneously. This parallelism is a game-changer, dramatically accelerating training times and allowing models to scale to unprecedented sizes and datasets. But how does it maintain sequential information without recurrence? The answer lies in its unique architecture, primarily driven by the self-attention mechanism and positional encodings.
The Core Idea: Parallel Processing and Attention
At its heart, the Transformer model posits that the critical ingredient for understanding sequences isn’t sequential processing, but rather the ability to weigh the relevance of different parts of the input to each other, regardless of their position. This is achieved through the “attention mechanism.” Specifically, the Transformer employs “self-attention,” which allows each element in an input sequence to “attend” to all other elements in the same sequence, identifying which elements are most relevant for processing the current element. Imagine reading a sentence: “The quick brown fox jumped over the lazy dog.” When you process the word “jumped,” your brain implicitly connects it to “fox” (the subject) and “dog” (the object) to understand the action. The self-attention mechanism computationally mimics this selective focus.
By processing all inputs in parallel and using self-attention to establish intricate relationships between tokens, the Transformer model achieves several profound advantages:
- Unlimited Context Window: Unlike RNNs with their limited hidden states, self-attention can directly connect any two words in a sequence, no matter how far apart, allowing it to capture true long-range dependencies.
- High Parallelizability: The absence of recurrence means that computations for different parts of the sequence can be performed simultaneously, leading to significantly faster training on GPUs and TPUs.
- Reduced Sequential Dependencies: Information flow is no longer strictly left-to-right; any token can instantly access information from any other token.
This foundational shift enabled the construction of models that could learn far more complex patterns and relationships within data, laying the groundwork for the extraordinary capabilities we witness in modern AI.
[INLINE IMAGE 1: place after second H2 | alt=”what is a transformer model concept illustration”]
Deconstructing the Transformer Architecture: Key Components Explained
The magic of the Transformer model lies in its elegant yet intricate architecture. While it eschews recurrence and convolution, it’s a sophisticated ensemble of several interconnected components, each playing a crucial role in its ability to process and generate sequences. Understanding these components is key to appreciating the model’s power.
At a high level, the original Transformer consists of an encoder stack and a decoder stack. The encoder processes the input sequence, building a rich contextual representation, while the decoder uses this representation to generate an output sequence, typically in a different language or format. Both stacks are composed of multiple identical layers.
The Encoder Stack: Processing Input Sequences
The encoder’s primary role is to take an input sequence (e.g., a sentence in English) and transform it into a sequence of continuous representations, or vectors, that capture the meaning and context of each word (or token) within the sentence. It consists of a stack of identical encoder layers. Each encoder layer has two main sub-layers:
- Multi-Head Self-Attention Mechanism: This is the core innovation. It allows the model to weigh the importance of all other words in the input sentence when processing a particular word. Instead of a single “attention head,” the Transformer uses multiple heads in parallel, each focusing on different aspects of the relationships between words. This diverse perspective enriches the contextual understanding.
- Position-wise Feed-Forward Network: A simple fully connected neural network applied independently and identically to each position (word) in the sequence. It acts as a processing step after attention, allowing the model to further transform the representations based on the information gathered by the attention mechanism.
Crucially, each sub-layer is augmented with a residual connection (adding the input of the sub-layer to its output) and layer normalization. Residual connections help with training very deep networks by allowing gradients to flow more easily, preventing vanishing gradients. Layer normalization stabilizes training by normalizing the activations across the features for each sample independently.
The Decoder Stack: Generating Output Sequences
The decoder stack, also composed of multiple identical layers, is responsible for generating the output sequence (e.g., the translated sentence in French) one token at a time, based on the contextual representations produced by the encoder. Each decoder layer has three main sub-layers:
- Masked Multi-Head Self-Attention: Similar to the encoder’s self-attention, but with a critical difference: it’s “masked.” This masking ensures that when predicting the next word, the decoder can only attend to words that have already been generated (or are to its left in the sequence) and not future words. This prevents the model from “cheating” by looking at the answer it’s trying to predict.
- Multi-Head Encoder-Decoder Attention: This sub-layer performs attention over the output of the encoder stack. It allows the decoder to focus on relevant parts of the input sequence while generating the output. This is where the communication between the encoder’s understanding of the input and the decoder’s generation of the output occurs.
- Position-wise Feed-Forward Network: Identical to the one in the encoder, it further processes the combined information from the two attention layers.
Like the encoder, each sub-layer in the decoder also employs residual connections and layer normalization. The output of the final decoder layer then passes through a linear layer and a softmax function to produce the probability distribution over the vocabulary for the next predicted token.
Multi-Head Self-Attention: The Brain of the Transformer
The self-attention mechanism is arguably the most brilliant and innovative component of the Transformer model. It enables the model to draw connections between different positions in a sequence to compute a representation for each position. For instance, in the sentence “The animal didn’t cross the street because it was too tired,” self-attention helps the model understand that “it” refers to “animal.”
Here’s how it generally works:
- Query, Key, Value (QKV): For each token in the input sequence, three vectors are generated: a Query (Q), a Key (K), and a Value (V). These are learned transformations of the token’s embedding.
- Calculating Attention Scores: To determine how much each word should “attend” to others, the Query vector of the current word is dot-producted with the Key vectors of all other words in the sequence. This produces a raw “attention score.”
- Scaling and Softmax: These raw scores are then scaled (to prevent very large values from dominating) and passed through a softmax function. Softmax normalizes the scores into a probability distribution, indicating how much “attention” each other word should get.
- Weighted Sum of Values: Finally, these attention probabilities are multiplied by the Value vectors of the corresponding words and summed up. The result is a new vector for the current word that is a weighted average of the Value vectors of all words in the sequence, with the weights determined by the attention scores. This new vector now incorporates contextual information from the entire sequence.
The “Multi-Head” aspect means that this attention process is performed multiple times in parallel, using different sets of learned Q, K, V matrices. Each “head” learns to focus on different types of relationships or different parts of the context. The outputs from these multiple heads are then concatenated and linearly transformed, providing a richer and more nuanced contextual representation.
Positional Encoding: Preserving Sequence Order
Since the Transformer processes all words in parallel and lacks recurrence, it has no inherent understanding of the order of words in a sequence. Without this, “dog bites man” would be indistinguishable from “man bites dog.” To remedy this, the Transformer injects “positional encodings” into the input embeddings. These are vectors that carry information about the absolute or relative position of each token in the sequence. These encodings are added to the input embeddings at the very beginning of the encoder and decoder stacks. They typically consist of sine and cosine functions of different frequencies, allowing the model to easily learn and generalize to longer sequences than those seen during training.
Feed-Forward Networks and Residual Connections
Beyond the attention mechanisms, each encoder and decoder layer includes a simple, fully connected feed-forward network. This network is applied independently to each position (token) and consists of two linear transformations with a ReLU activation in between. It serves to further process the representations produced by the attention layers, adding non-linearity and allowing the model to learn more complex patterns. As mentioned, residual connections and layer normalization are critical features throughout the architecture, providing stability and facilitating the training of very deep Transformer models by allowing gradients to flow more smoothly through the network.
Why Transformers Became a Game-Changer: Unpacking Their Advantages
The architectural innovations of the Transformer model translated into a cascade of practical advantages that rapidly cemented its status as the foundational architecture for modern AI. Its impact was not merely incremental but represented a qualitative leap in capabilities, particularly for tasks involving sequential data.
Eliminating Recurrence: Speed and Scalability
The most immediate and impactful advantage of the Transformer’s design is its complete abandonment of recurrence. RNNs, by their nature, must process tokens sequentially. If you have a sentence of 100 words, the 100th word’s processing cannot begin until the 99th word is done. This creates a bottleneck that prevents parallel computation. In contrast, the Transformer processes all input tokens simultaneously. This parallelism allows for:
- Faster Training: Modern computing hardware, especially GPUs and TPUs, is optimized for parallel operations. By allowing computations across the entire sequence to happen at once, Transformers can be trained significantly faster than RNNs, reducing training times from weeks to days or even hours for massive datasets.
- Scalability to Enormous Datasets: The ability to train faster means that Transformers can leverage vastly larger datasets. This access to more data, combined with their capacity to learn complex patterns, is a key reason behind the incredible performance of modern large language models.
- Handling Longer Sequences: While RNNs struggled with “long-term dependencies” due to vanishing gradients over extended sequences, Transformers can theoretically process sequences of arbitrary length because any word can directly attend to any other word, regardless of their distance. This provides a much more robust mechanism for capturing context over long passages of text or other sequential data.
Capturing Context: The Power of Self-Attention
The self-attention mechanism is the true intellectual core of the Transformer’s success. It allows the model to dynamically weigh the importance of every other token in the input sequence when processing a given token. This is a far more nuanced and powerful way of understanding context compared to the fixed-size hidden states of RNNs. Consider the ambiguity of words like “bank” (river bank vs. financial institution). Self-attention allows the model to look at surrounding words (“river,” “money”) and assign higher relevance to the correct contextual clues, resolving the ambiguity directly.
Key benefits of self-attention include:
- Global Contextual Understanding: Every token’s representation is influenced by every other token, creating a truly global contextual understanding rather than a localized one.
- Dynamic Weighting: The relevance weights are not fixed but learned dynamically for each input sequence, adapting to the specific context.
- Interpretability (to an extent): While deep learning models are often “black boxes,” the attention weights can sometimes offer insights into which parts of the input the model focused on when making a decision, providing a degree of explainability.
Versatility and Transfer Learning Capabilities
The Transformer’s architecture proved remarkably versatile. Its ability to learn rich, contextual embeddings from vast amounts of unlabeled data, combined with its parallelizability, made it perfectly suited for the paradigm of “pre-training and fine-tuning.”
- Pre-training: A large Transformer model can be pre-trained on a massive corpus of text (e.g., the entire internet) using self-supervised tasks (like predicting masked words or the next sentence). During this phase, the model learns a deep understanding of language structure, grammar, semantics, and even some world knowledge without explicit labels.
- Fine-tuning: Once pre-trained, this highly knowledgeable model can then be fine-tuned on smaller, task-specific labeled datasets (e.g., sentiment analysis, question answering). The pre-trained knowledge acts as a powerful starting point, requiring far less task-specific data and achieving significantly better performance than training a model from scratch.
This transfer learning paradigm, pioneered by models like BERT and GPT, unlocked unprecedented performance across a multitude of NLP tasks and became a blueprint for much of modern AI development. The same principles have since been extended to computer vision (Vision Transformers), audio, and multimodal tasks, showcasing the architecture’s inherent adaptability.
The combination of these advantages – unparalleled speed, global contextual awareness, and transferability – fundamentally shifted the landscape of AI research and application, paving the way for the sophisticated and intelligent systems we interact with today.
[INLINE IMAGE 2: place after fourth H2 | alt=”what is a transformer model comparison illustration”]
Key Applications and Impact Across Industries
The theoretical elegance and practical advantages of the Transformer model quickly translated into revolutionary advancements across a multitude of domains. Its impact has been so profound that it’s difficult to find an area of AI development that hasn’t been touched or transformed by this architecture. In 2026, Transformers are not just academic curiosities; they are integral to the products and services that define our digital world.
Revolutionizing Natural Language Processing (LLMs, Translation, Summarization)
NLP was the original proving ground for the Transformer, and it remains its most prominent application area. The ability to model long-range dependencies and capture nuanced context has led to breakthroughs that were previously unimaginable:
- Large Language Models (LLMs): This is arguably the most impactful application. Models like OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, and countless others are all built on the Transformer architecture. These LLMs can generate coherent, contextually relevant, and even creative text, perform complex reasoning, answer questions, write code, and engage in sophisticated conversations. They power advanced chatbots, virtual assistants, content creation tools, and educational platforms.
- Machine Translation: Transformer models have drastically improved the quality and fluency of machine translation. Google Translate and similar services leverage Transformers to provide near real-time, highly accurate translations across dozens of languages, understanding grammatical structures and semantic nuances far better than previous systems.
- Text Summarization: From condensing lengthy research papers to summarizing news articles, Transformers excel at generating concise and accurate summaries, extracting key information while preserving meaning.
- Sentiment Analysis & Text Classification: Transformers can accurately discern the emotional tone of text or categorize it into predefined topics, crucial for customer service, market research, and content moderation.
- Question Answering: These models can read a passage of text and answer complex questions based on the information contained within, demonstrating a deep comprehension of the content.
- Code Generation and Completion: Specialized Transformer models like GitHub Copilot can assist developers by generating code snippets, completing lines, or even translating natural language descriptions into functional code, dramatically boosting productivity.
Beyond Text: Transformers in Computer Vision
While initially designed for sequences of text, researchers soon realized the Transformer’s self-attention mechanism could be applied to other forms of sequential or structured data, including images. Images can be broken down into sequences of “patches” or tokens, allowing Transformers to process them. This led to the emergence of Vision Transformers (ViTs) and their successors, challenging the long-standing dominance of Convolutional Neural Networks (CNNs) in computer vision:
- Image Classification: ViTs have achieved state-of-the-art results on image classification benchmarks, demonstrating their ability to capture global relationships between different parts of an image.
- Object Detection & Segmentation: Advanced Transformer-based models are used for identifying and localizing objects within images and videos, and even segmenting them precisely, critical for autonomous vehicles, medical imaging, and surveillance.
- Image Generation & Editing: Models like DALL-E, Stable Diffusion, and Midjourney, which generate photorealistic images from text prompts, are potent examples of Transformers’ multimodal capabilities. They bridge language understanding with image synthesis.
- Video Understanding: By treating video frames as sequences, Transformers can analyze actions, events, and spatial-temporal relationships in videos, vital for content analysis, sports analytics, and security.
Expanding Horizons: Audio, Robotics, and Scientific Discovery
The versatility of the Transformer architecture means its influence continues to expand into unexpected areas:
- Audio Processing: Transformers are increasingly used for speech recognition, speaker identification, and even music generation, treating audio signals as sequences of features.
- Robotics: In robotics, Transformers can process sensor data, plan complex action sequences, and even learn dexterous manipulation tasks, often in conjunction with reinforcement learning. They help robots understand human commands and interact with dynamic environments.
- Drug Discovery and Materials Science: By modeling sequences of molecules, proteins, or genetic code, Transformers are accelerating drug design, predicting protein structures (e.g., AlphaFold’s success heavily relies on Transformer-like attention mechanisms), and discovering new materials properties. They can learn the complex relationships between molecular structure and function.
- Financial Forecasting: In some experimental applications, Transformers are used to analyze time-series data, such as stock prices or economic indicators, to identify patterns and make predictions.
The profound impact of the Transformer model is not just about incremental improvements; it’s about enabling entirely new paradigms of AI functionality. Its ability to learn complex, long-range dependencies across diverse data types makes it a cornerstone technology for the future of intelligent systems, driving innovation across nearly every industry.
The Ecosystem of Transformer Models: Major Architectures and Variants
The original “Attention Is All You Need” paper laid the foundational architecture, but the field quickly diversified. Researchers adapted, optimized, and extended the Transformer, leading to a vibrant ecosystem of specialized models, each excelling in particular tasks or possessing unique characteristics. Understanding these variants is crucial for appreciating the breadth of Transformer capabilities.
Encoder-Only Models: Understanding Context (e.g., BERT, RoBERTa)
These models utilize only the encoder stack of the Transformer architecture. Their primary purpose is to generate rich, contextualized embeddings for input sequences. They are typically pre-trained on massive text corpora using self-supervised objectives, such as predicting masked words (Masked Language Model – MLM) or identifying if two sentences follow each other (Next Sentence Prediction – NSP).
- BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, BERT was a landmark model. Its key innovation was bidirectional pre-training, meaning it considered context from both the left and right of a word simultaneously. This allowed it to achieve a deeper understanding of language than previous unidirectional models. BERT is excellent for tasks requiring a deep understanding of input text, such as sentiment analysis, question answering (where it can identify the exact span of text that answers a query), and text classification.
- RoBERTa (Robustly Optimized BERT Approach): A refinement of BERT by Facebook AI, which showed that BERT’s performance could be significantly improved by training it longer, on more data, with larger batch sizes, and by dynamically masking tokens. It demonstrated that simply optimizing training procedures could yield substantial gains.
- DistilBERT: A smaller, faster, and lighter version of BERT, developed by Hugging Face. It retains much of BERT’s performance while being more efficient, suitable for deployment in resource-constrained environments.
Encoder-only models are typically fine-tuned for specific “understanding” tasks by adding a small task-specific layer on top of their contextual embeddings.
Decoder-Only Models: Generative Powerhouses (e.g., GPT series, LLaMA)
These models leverage only the decoder stack of the Transformer, often without the encoder-decoder attention mechanism (as there’s no encoder output to attend to). Their strength lies in text generation. They are usually pre-trained as unidirectional language models, meaning they predict the next word in a sequence based on all preceding words.
- GPT (Generative Pre-trained Transformer) Series: Developed by OpenAI, these models are arguably the most famous examples of decoder-only Transformers. From GPT-1 to GPT-4 and beyond, they demonstrate incredible capabilities in generating coherent, creative, and contextually appropriate text. Their primary pre-training objective is next-token prediction. They excel at tasks like creative writing, dialogue generation, summarization, and even reasoning by formulating problems as text generation tasks.
- LLaMA (Large Language Model Meta AI) & LLaMA 2: Developed by Meta AI, the LLaMA family of models became highly influential due to their open-source nature (for research and commercial use, respectively), enabling widespread innovation and the development of countless derivative models (e.g., Alpaca, Vicuna). They showcase that competitive performance can be achieved with smaller, more efficient models when trained on vast datasets.
- Mistral AI Models (e.g., Mistral 7B, Mixtral 8x7B): Emerging players that have demonstrated exceptional performance for their size, often leveraging advanced techniques like Grouped-Query Attention and Mixture-of-Experts (MoE) architectures to achieve high efficiency and quality.
Decoder-only models are the backbone of most generative AI applications, from sophisticated chatbots to content creation engines.
Encoder-Decoder Models: Translation and Sequence-to-Sequence (e.g., T5, BART)
These models employ both the encoder and decoder stacks, faithfully following the original Transformer architecture. They are ideal for “sequence-to-sequence” tasks where an input sequence is transformed into a potentially different output sequence.
- T5 (Text-to-Text Transfer Transformer): Developed by Google, T5’s core idea is to frame *every* NLP problem as a “text-to-text” task. Whether it’s translation, summarization, question answering, or classification, the input is text, and the output is text. This unified approach simplified task design and showed strong performance across a wide range of benchmarks.
- BART (Bidirectional and Auto-Regressive Transformers): Developed by Facebook AI, BART combines the pre-training objectives of BERT (masking tokens) with a GPT-like generative objective (auto-regressive decoding). It’s particularly strong for tasks requiring both understanding and generation, such as summarization and text generation.
These models are particularly effective for tasks like machine translation, abstractive summarization (where the summary might include new words not in the original text), and other complex transformations of text.
Vision Transformers (ViT) and Their Innovations
The application of Transformers to computer vision marked a significant cross-domain transfer of technology. Vision Transformers treat images not as a grid of pixels but as a sequence of image “patches.”
- Vision Transformer (ViT): Introduced by Google, ViT was the first model to successfully apply the pure Transformer architecture directly to image classification. It divides an image into fixed-size patches, linearly embeds them, adds positional encodings, and feeds them to a standard Transformer encoder. It demonstrated that Transformers could outperform CNNs on large datasets, especially when pre-trained on massive amounts of image data.
- Swin Transformer: Addresses the computational cost of ViTs for high-resolution images by introducing “shifted windows.” Instead of global self-attention across the entire image, Swin Transformers compute self-attention within local windows and then shift these windows in successive layers, allowing for cross-window connections and hierarchical feature learning, making them more efficient and suitable for dense prediction tasks like object detection and segmentation.
- DALL-E, Stable Diffusion, Midjourney: While not pure ViTs, these multimodal generative models often incorporate Transformer or attention-based components (e.g., in their U-Net backbones or text encoders) to bridge the gap between text prompts and image generation, representing a powerful synthesis of vision and language understanding.
Other Noteworthy Variants and Specialized Architectures
The rapid pace of innovation has led to countless other specialized Transformer models:
- Sparse Transformers: Address the quadratic complexity of self-attention (where attention scales with the square of the sequence length) by allowing each token to attend only to a subset of other tokens, making them more efficient for very long sequences.
- Long-Context Transformers (e.g., Longformer, BigBird, Perceiver IO): Focus on enabling Transformers to handle extremely long sequences (e.g., entire books, long codebases) by using various forms of sparse attention or by re-framing the attention mechanism to scale more efficiently.
- Mixture-of-Experts (MoE) Models: These models incorporate multiple “expert” neural networks within their layers. During inference, a “router” mechanism selects which expert (or combination of experts) to use for processing a given input token, allowing the model to have billions of parameters while only activating a fraction of them for any given input, leading to higher efficiency and specialized knowledge. Google’s Switch Transformer and Mistral’s Mixtral are prominent examples.
This dynamic ecosystem showcases the Transformer’s adaptability and the relentless pursuit of more efficient, powerful, and specialized AI models. As research continues, we can expect even more innovative variants to emerge, pushing the boundaries of what these architectures can achieve.
Comparison of Key Transformer Model Architectures Model Family Architecture Type Primary Use Cases Key Innovation / Characteristics BERT / RoBERTa Encoder-Only Text classification, Question Answering, Sentiment Analysis, Named Entity Recognition Bidirectional pre-training (Masked Language Model, Next Sentence Prediction), deep contextual understanding. GPT Series (e.g., GPT-3, GPT-4) Decoder-Only Text generation, Conversational AI, Creative writing, Code generation, Summarization Unidirectional (auto-regressive) pre-training, massive scale, emergent few-shot learning capabilities. T5 / BART Encoder-Decoder Machine Translation, Abstractive Summarization, Text-to-Text conversion for various tasks Unified text-to-text framework (T5), combined denoising/generative pre-training (BART), versatile for sequence-to-sequence. Vision Transformer (ViT) / Swin Encoder (applied to image patches) Image Classification, Object Detection, Image Segmentation Applying pure Transformer to vision by treating image patches as tokens (ViT); hierarchical attention with shifted windows for efficiency (Swin). LLaMA / Mistral (MoE) Decoder-Only (often) General-purpose LLM, chat, coding, instruction following Focus on efficiency, open-source accessibility (LLaMA); Mixture-of-Experts for high performance at lower inference cost (Mixtral). Challenges and Limitations of Transformer Models
Despite their unparalleled success and transformative impact, Transformer models are not without their limitations and challenges. As their scale and deployment continue to grow in 2026, understanding these drawbacks becomes increasingly critical for responsible development and realistic application.
The Scale Problem: Computational Demands and Energy Footprint
One of the most significant challenges associated with Transformer models is their insatiable appetite for computational resources. The fundamental self-attention mechanism, while powerful, scales quadratically with the length of the input sequence. This means that if you double the length of a sequence, the computational cost of attention quadruples. For very long documents, this quickly becomes prohibitive.
- High Training Costs: Training the largest Transformer models (like GPT-4 or Gemini) requires vast amounts of computing power, consuming millions of dollars in electricity and thousands of GPU-hours. This creates a high barrier to entry for smaller organizations and researchers, centralizing AI development among a few tech giants.
- High Inference Costs: Even after training, running these models for inference (making predictions or generating text) can be computationally intensive, leading to significant operational costs, especially for real-time applications.
- Environmental Impact: The enormous energy consumption associated with training and deploying these models raises serious environmental concerns, contributing to carbon emissions. Researchers are actively working on “green AI” solutions to mitigate this.
- Memory Constraints: The attention mechanism also demands significant memory to store the attention weights and intermediate activations, further limiting the maximum sequence length that can be processed on available hardware.
While innovations like sparse attention, linear attention, and Mixture-of-Experts (MoE) architectures are attempting to alleviate these issues, the fundamental scaling properties remain a significant hurdle for extremely long contexts or ubiquitous edge deployment.
Data Dependency and the “Garbage In, Garbage Out” Dilemma
Transformer models, especially large language models, are incredibly data-hungry. Their impressive capabilities stem from being trained on vast amounts of text and other data, often scraped from the internet. This reliance on massive datasets introduces several problems:
- Quality of Data: The internet is full of noisy, biased, and often incorrect information. If the training data contains these flaws, the model will learn and replicate them. This is the “garbage in, garbage out” problem on a grand scale.
- Bias Amplification: Societal biases present in the training data (e.g., gender stereotypes, racial prejudices, political leanings) are absorbed and amplified by the model, potentially leading to unfair, discriminatory, or harmful outputs.
- Hallucination: Even with vast data, models can sometimes generate plausible-sounding but entirely fabricated information or make logical errors. They learn patterns and statistics from data, not necessarily deep factual understanding or common sense.
- Out-of-Distribution Data: Transformers perform best on data similar to their training distribution. When confronted with novel or significantly different data, their performance can degrade gracefully or catastrophically.
Curating, filtering, and cleaning such colossal datasets is an immense challenge, and ensuring data quality and ethical sourcing is an ongoing, complex task for the AI community.
Interpretability and Explainability: A Black Box Conundrum
Like many deep neural networks, Transformer models are largely “black boxes.” It’s difficult to understand precisely *why* a model makes a particular decision or generates a specific output. While attention weights can offer some hints about which parts of the input were important, they don’t provide a complete causal explanation. This lack of interpretability poses problems for:
- Trust and Reliability: In critical applications (e.g., medical diagnosis, legal advice, autonomous systems), being able to explain a decision is paramount for trust, accountability, and



